
Neural Networks – Simply Explained in 10 Minutes#
ChatGPT is just a neural network too …#
LLMs (Large Language Models) like ChatGPT – and generative AI (artificial intelligence) in general – have triggered quite a hype. In my opinion: absolutely rightly so! For me, ChatGPT is the eighth wonder of the world – perhaps a bit dramatic. But anyone who has worked with it for a while knows what I mean.
Although I’ve been working with AI for years, I never would have expected this steep development in such a short time. The all-knowing AI assistant we once only knew from science fiction movies has suddenly become reality. Today, she sits right in front of us – we can chat, talk, and ask her for advice on our everyday problems.
Many people now use AI assistants daily – but how do these marvels actually work? Where are their strengths, and where are their weaknesses? These are exactly the questions I explore in this article.
But before we look at what’s going on under the hood of LLMs like ChatGPT, we need a basic understanding of neural networks. Because like all modern AI marvels, ChatGPT – and comparable systems – are based on deep learning, whose foundation is artificial neural networks.
Programming vs Learning#
Computer programs like MS Office®, Acrobat Reader®, Photoshop®, or even websites are traditionally developed “by hand” in a programming language – and ultimately translated into a language the computer understands: machine language – the only language a processor can directly process.
Classical programs use algorithms, variables, and control structures like loops and conditions. They operate deterministically – the same input always leads to the same output. They work tirelessly, but without learning. A software automaton without a “brain”.
Our Brain as Inspiration#
As early as the 1950s, more than 70 years ago, science already had a concrete idea of how our brain roughly works. This led to the construction of the first artificial “brain cell”: the perceptron. It could process simple signals and was even capable of learning – but still had difficulties with more complex logical tasks.
From Perceptron to Artificial Neuron#
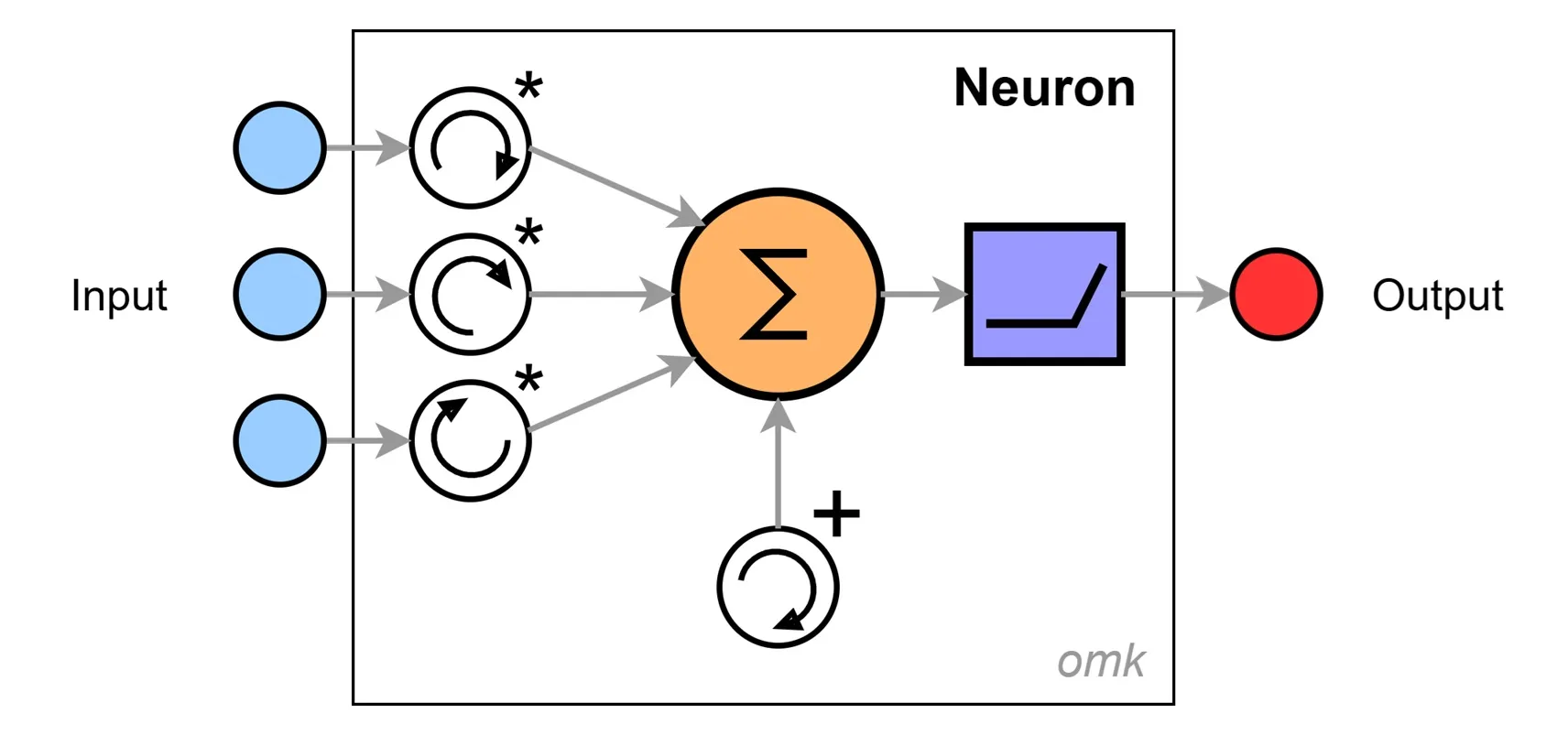
The artificial neuron is a simplified representation of a neuron from our brain. A small black box in which various input signals are processed into a single output signal.
The individual inputs are weighted – meaning their signals are amplified or weakened depending on their significance. They are then summed up, and a threshold – the so-called bias – is added. The bias allows the overall signal level to be raised or lowered.
All parameters like weights and bias are adjustable – this is what makes the neuron capable of learning.
And there we have it: our learning-capable computational unit – surprisingly simple.
Activation Brings Logic into Play#
For neural networks to solve more complex logical problems, an appropriate activation function is needed. It determines whether and how a signal is passed on within the network – essentially a neural switch or data router.
In the past, various activation functions such as Sigmoid, Tanh, or Softsign were used.
Today, only 2 main functions are commonly used:
- ReLU (Rectified Linear Unit) for feature extraction ➔ used for pattern recognition
- Softmax for classification ➔ outputs a probability distribution
Learning Made Simple#
- The input signals should lead to a defined output signal.
- If the result deviates, we adjust the settings: the weights to amplify or suppress signals – and additionally the bias to raise or lower the overall signal.
- We repeat this process – until we’re satisfied with the result …
👉 Here you can experiment with inputs, weights, bias, and activation – and see what comes out in the end.#
One Brain Cell Does Not Make a Brain#
A human brain consists of about 86,000,000,000 (86 billion!) neurons – even if that might not be expected in some people :-).
An overwhelming number of small “computers” and “switches”, complex and tightly interconnected. Their connections run crisscross through the brain and even occupy most of its volume. Only this far-reaching network enables the impressive cognitive abilities of humans.
And in the same way, an artificial neural network also doesn’t consist of just one neuron, but of a large number of closely connected neurons.
The capabilities of such networks are fascinating. It doesn’t have to be ChatGPT with billions of parameters – even with just a handful of neurons, surprisingly complex problems can be solved.
Neural Networks – Pattern Recognition Experts#
One ability that neural networks – especially deep neural networks – are impressively good at is recognizing patterns in data.
- ChatGPT® recognizes patterns in text
- Dall-E® recognizes patterns in images
- Sora® recognizes patterns in videos
- Whisper® recognizes patterns in audio files
In precisely this discipline, AI has now far surpassed us humans – and this ability forms the foundation of many current AI tools and today’s AI hype.
Recognizing Handwritten Digits – With Only 34 Neurons#
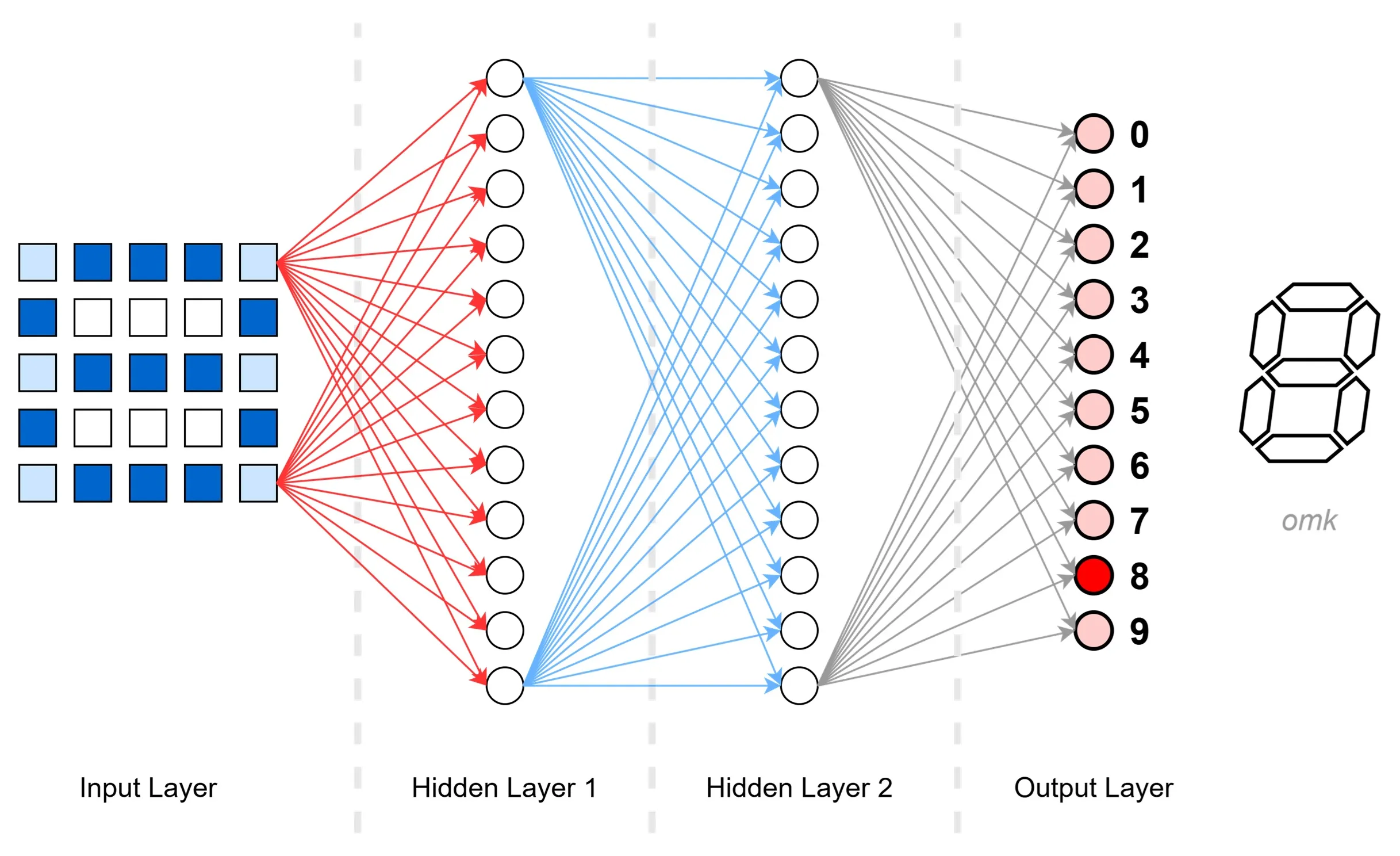
A simple neural network – with just 34 neurons – can reliably recognize handwritten digits.
This type of network is called an FFN (Feed-Forward Network) or FCN (Fully Connected Network).
It is the most commonly used type of neural network. Each neuron in one layer is connected to all neurons in the next layer.
The signals always flow in one direction: forward – with no feedback loops.
How Does It Work?!#
Input Layer – The Start#
Using a scanner, we digitize a single digit into a 5×5 matrix – that is, 25 pixels in varying shades of gray, from light to dark. The darker the pixel, the stronger the signal.
All 25 pixels are connected to all neurons in the next layer – the Hidden Layer 1.
(For better clarity, the image shows only two connected pixels. In reality, each neuron in one layer is connected to all neurons in the next layer – typical for a fully connected network.)
Hidden Layer 1 – Extracting Initial Features#
The neurons in this layer now process the input signals. Their goal: to identify features that point to a specific digit. Each computation step follows the same pattern:
- Weighted multiplication:
Each input signal is multiplied by its corresponding weight. - Summing the signals:
All weighted signals are added together into a total sum ∑. - Adding bias:
A bias value is added to adjust the signal level. - Activating with ReLU:
The ReLU function determines whether and how strongly the signal is passed to the next layer.
This layer is also fully connected to the next layer.
Hidden Layer 2 – Extracting Additional Features#
In this layer, technically the same thing happens as in Hidden Layer 1:
The input data is processed again, this time identifying additional – and mostly more abstract – features.
The signals are then passed on to the target layer using the activation function: the output layer.
Output Layer – The Decision#
This layer now makes the final decision: Which digit was written?
Based on the previously extracted features, the network selects the most likely digit.
For this, we don’t use the ReLU activation function – it’s responsible for feature detection.
Instead, we now use the Softmax function: a classification function that outputs a probability for each possible digit.
In our example, the network recognizes the digit with the highest probability – a 8.
Where and How Exactly Was the Digit Recognized?#
The astonishing answer: We don’t really know!
The network recognizes digits based on self-learned, abstract features – without us being able to fully understand what it actually recognized.
For us humans, this is hard to grasp: there are no clearly defined rules like:
“An 8 consists of two stacked circles.”
Instead, each layer in the network discovers its own patterns in the data.
The deeper the layer, the more abstract these features become.
- The first layer detects simple dots and lines, for example
- The second layer identifies corners, curves, or fragments
- Further layers combine this information into more complex structures
The Problem of Explainability and Traceability#
It’s hard to say why the network decides that a certain input is not the digit 3 – or which neuron was activated for what reason.
There are indeed methods to visualize the activity of individual neurons, but especially with large networks, one quickly reaches the limits.
The explainability and traceability of the results remain one of the biggest challenges in modern AI.
Problem Case: No Digit Recognized#
What happens if the input contains no digit at all – for example, a letter?
Many networks do not have a separate class like “no digit.” Instead, the model outputs probabilities for known classes – even when there is actually nothing suitable present.
The result: multiple digits receive similar probabilities, the model is uncertain – and usually just displays the most likely looking, but wrong digit.
Inference – Using the Model#

Our “digit recognition machine” is an already trained neural network – a so-called model.
The application of such a model is called inference.
After training, the model remains static – it no longer adapts during use.
Inference – in other words, recognizing the digits – is technically a comparatively simple process:
The processing is fast and requires only minimal computing power.
Training a neural network, on the other hand – the actual learning process where the model learns to reliably recognize patterns – is significantly more complex.
Training the Model ➔ Complex and Costly#
The goal of a neural network is usually to recognize complex patterns in data – such as text in images, speech in audio files, or distinguishing between cats and dogs in photos.
But a network can’t do that on its own.
We first have to train it – that is, teach it what a digit looks like, or what distinguishes a dog from a cat.
The (Actually) Simple Solution#
We show the network many different examples – and then evaluate the result:
Did the network correctly recognize the pattern?
If the result deviates from what was expected, we adjust the controls:
We modify the input weights and the bias – for each individual neuron.
In the 1950s, this was actually done by hand – a lot of work, but the networks were still quite small back then.
It stayed that way for decades – until some smart minds in the 1980s came up with the brilliant idea to automate the process.
Backpropagation – Now AI Learns Automatically#
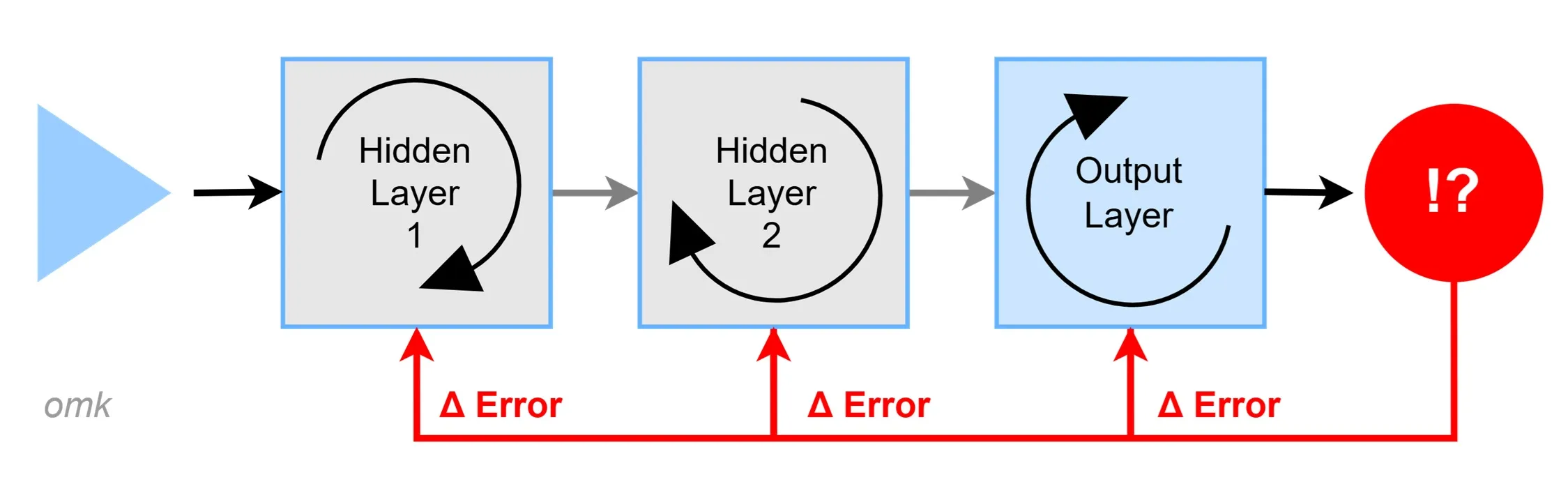
The Basic Idea#
For a neural network to learn, it must know how well it performed.
To do this, the result calculated by the network is compared with the expected result.
From this difference, an error measure is calculated – the so-called loss.
The greater the difference, the greater the error – and thus the need for correction.
Error Distribution and Adjustment#
Since many neurons are involved in producing the result, the error is distributed backward through the entire network using backpropagation.
For each individual neuron, it is calculated how much its weights and bias contributed to the total error.
These parameters are then adjusted so that the error becomes smaller.
The process is complex and mathematically demanding:
- Gradient descent:
An optimization algorithm that determines in which direction and by how much the parameters need to be changed to minimize the error. - Chain rule of differential calculus:
It allows for the efficient calculation of error propagation layer by layer – even in very deep networks.
This training process is repeated many times – so-called epochs.
After each epoch, the model gets a little better. And eventually, it becomes accurate enough to be used.
From that point on, the inference phase begins – that is, using the trained model.
However, this process is time-consuming, requires a lot of computing power, and is therefore expensive – especially for large networks.
In Training, We Distinguish Between Three Basic Methods#
Supervised Learning:
In supervised learning, we show the model labeled data – that is, data where the desired outcome is already known.
In our example, this would be an image of a digit with a label stating which digit it represents.
The model can then detect the difference between its prediction and the actual answer – and learn from it.Unsupervised Learning:
Here, we present the model with unlabeled, raw data. It receives no hints – and tries to recognize patterns or structures in the data on its own.
For example, it groups similar data – this is called clustering.
What’s interesting: LLMs like ChatGPT were technically trained using unlabeled texts from the internet – but with the help of so-called self-supervised learning methods.
These methods generate “internal labels” during training – more on that later.Reinforcement Learning:
The model (or “agent”) learns through rewards and penalties how to behave better next time.
This method is used, for example, to master games – or in ChatGPT through Reinforcement Learning from Human Feedback (RLHF), which is often applied after the initial pretraining for fine-tuning.
Does the Model Pass the Test?#
How do we check whether a trained model is actually any good?
After training the network with many examples and reducing the error (loss) to a sufficiently low level, we must ensure that it hasn’t simply memorized the data.
Instead, it should be able to transfer the learned patterns to new, unseen data – this is called generalization ability.
To do this, we split the dataset – for example, with 1,000 images – into two parts:
We use 800 images for training, and hold back the remaining 200 images to test the model later.
If the model can reliably recognize these new images – ones it has never seen during training – then it is considered generalized and suitable for practical use.
Clean Data: The Key to Success#
The saying: “You are what you eat” – also applies to neural networks.
For a model to reliably recognize patterns, the training data must be accurate, complete, and of high quality.
If a network is trained, for example, with noisy or poorly lit images of cats and dogs, the results will – unsurprisingly – be mediocre.
Bias, misinformation, or poor quality in the training data directly affect the model’s behavior – with potential ethical consequences.
A powerful model therefore requires:
- High data quality: Error-free, accurate, and consistent
- Data diversity: Different variants, perspectives, and contexts
- Verified data: True, credible, and validated
- Cleaned data: Remove errors, outliers, and duplicates
- Normalized values: Uniform scales, e.g., for brightness or pixel values
- Representative data: Relevant examples for all application scenarios
- Up-to-date data: Current and contextually appropriate
Initial Conclusion#
Neural networks are powerful tools, but not magic. They learn, recognize patterns, draw conclusions – and can greatly assist us in everyday life.
But: for them to work reliably, they need a well-thought-out design and above all clean, diverse, and up-to-date data.
Faulty, biased, or outdated data inevitably lead to flawed results.
What We Can Take Away for Our LLM Understanding#
- Neural networks are not traditionally programmed, but instead learn independently to recognize patterns in data.
- Data quality is crucial: Poor, incorrect, or inconsistent data leads to poor results – garbage in, garbage out.
- Training is computationally intensive and time-consuming. Only after training is complete does the network become a finished model ready for use (→ inference).
- After training, the model parameters are fixed – meaning:
The neural network does not learn anything new during usage, it is static. - Learning occurs through the adjustment of weights and bias values – these are called parameters.
- The activation function determines how signals are passed on – e.g., for feature extraction (ReLU) or classification (Softmax).
- Neural networks always provide an answer – even if none of the options are actually correct.
In such cases, they present the most likely, but possibly incorrect solution. - Deep neural networks (DNNs) have many hidden layers – starting at around 3, they are typically referred to as “deep”.
- The decisions of such networks are hard to trace – because they are based on the activity of thousands or even millions of neurons.
Explainability remains an open challenge.
© 2025 Oskar Kohler. All rights reserved.Note: The text was written manually by the author. Stylistic improvements, translations as well as selected tables, diagrams, and illustrations were created or improved with the help of AI tools.