
Künstliche Intelligenz (KI) – mehr als nur ein Hype?#
Alle reden über Künstliche Intelligenz – ein Hype, der in aller Munde ist. Täglich hört man von den erstaunlichen Fähigkeiten moderner Sprachmodelle wie ChatGPT, Gemini, Granite und vielen anderen.

Obwohl es Künstliche Intelligenz (KI) und Neuronale Netze schon seit Jahrzehnten gibt – etwa für
- Filmempfehlungen
- Produktvorschläge
- Werbeoptimierung
- Bonitätsprüfungen
löste ChatGPT Ende 2022 einen weltweiten Hype aus.
Warum war das so?#
KI war zuvor meist unsichtbar im Hintergrund aktiv: Sie unterstützte Geschäftsprozesse, half bei Analysen oder steuerte Personalisierungen, ohne dass Endnutzer sie direkt wahrnahmen.

Erst mit der Veröffentlichung des großen Sprachmodells (LLM) ChatGPT durch OpenAI konnten plötzlich Millionen Menschen selbst erleben, wie leistungsfähig moderne KI-Systeme sind:
- Texte schreiben
- Erklären
- Zusammenfassen
- Ideen liefern
- Programmieren
Und das alles in natürlicher Sprache – scheinbar mühelos. Damit rückt die KI in Bereiche vor, die lange als kreative Domäne des Menschen galten: Sprache verstehen, Wissen verknüpfen, neue Ideen hervorbringen.
Innerhalb von nur 2 Monaten erreichte ChatGPT bereits über 100 Millionen Nutzer – ein Rekord, der es zum am schnellsten wachsenden digitalen Produkt der Geschichte machte.
Damit wurde KI zum ersten Mal unmittelbar erfahrbar für jedermann, nicht nur für Experten oder Unternehmen. Dieser direkte Zugang erklärt den enormen Hype – und markiert einen Wendepunkt in der öffentlichen Wahrnehmung von Künstlicher Intelligenz.
KI – sicher mehr als nur ein Hype#
Ist das alles nur heiße Luft? Meiner Meinung nach nicht. Vielmehr stehen wir wahrscheinlich mitten in einer der größten technologischen Revolutionen unserer Zeit – mit Auswirkungen, die weit über einzelne Branchen hinausgehen werden.
Heute gibt es nicht nur ChatGPT, sondern viele weitere Mitbewerber wie Gemini (Google), Granite (IBM), LLaMA (Meta), Mistral, DeepSeek und zahlreiche andere.
Die rasanten Entwicklungen und Erfolge sind inzwischen kaum mehr vollständig zu überblicken.
Doch gerade deshalb stellt sich die spannende Frage:
Warum überhaupt eine KI auf der eigenen Hardware betreiben, wenn es so viele leistungsstarke Modelle in der Cloud gibt?
Warum eine eigene KI betreiben?#
Stellen wir uns vor, wir könnten Sprachmodelle lokal installieren – welche Vorteile würde das mit sich bringen?
- Spezialisierung – Lokale Modelle können gezielt auf eigene Daten oder Fachgebiete zugeschnitten werden.
- Kosten – Nach der Einrichtung entstehen keine laufenden API- oder Abo-Kosten, nur Strom- und Hardwareaufwand.
- Performance – Für viele Anwendungen reicht die Geschwindigkeit lokaler Modelle aus, besonders mit optimierten Versionen.
- Latenz – Abfragen laufen direkt auf der eigenen Hardware, ohne Umweg über die Cloud.
- Sicherheit & Datenschutz – Alle Daten bleiben lokal, nichts verlässt den eigenen Rechner oder das Unternehmensnetzwerk.
- Flexibilität – Nutzer entscheiden selbst, welche Modelle und Tools sie einsetzen.
- Finetuning – Modelle lassen sich mit eigenen Daten nachtrainieren und damit optimal anpassen.
- Vielfalt der Modelle – Es gibt viele offene Modelle (z. B. LLaMA, Mistral, Falcon, DeepSeek), die je nach Bedarf eingesetzt werden können.
- Offline-Nutzung – Auch ohne Internetzugang bleibt die KI einsatzfähig.
- Keine externen Beschränkungen – Keine Limits bei Abfragen oder Abhängigkeit von Nutzungsbedingungen Dritter.
- Individuelle Sicherheitseinstellungen – Man kann selbst entscheiden, welche „Guardrails“ oder Sicherheitsfilter aktiv sein sollen – oder eben nicht.
Die nächste spannende Frage lautet: Ist es überhaupt möglich, so große Sprachmodelle lokal zu betreiben?
Die ganz großen Modelle – etwa GPT-5 (OpenAI), Gemini 2.5 Pro (Google) oder Claude Opus 4 (Anthropic) – werden weder Privatnutzer noch die meisten Unternehmen lokal installieren können. Sie laufen in riesigen Rechenzentren mit Millionen spezialisierter Recheneinheiten (GPUs/TPUs/NPUs) und erfordern eine Infrastruktur, die außerhalb von Hyperscalern (Google, Microsoft, Meta, Amazon usw.) nicht realistisch ist.
- GPU: Grafikprozessor, heute auch für parallele KI-Berechnungen.
- TPU: Spezialisierte Google-Hardware für effiziente Tensor-Operationen.
- NPU: Energiesparender KI-Beschleuniger für mobile und Edge-Geräte.
Ja, es gibt sie wirklich: große Sprachmodelle für den lokalen Einsatz#

Aber: Es ist durchaus möglich, leistungsstarke offene Sprachmodelle lokal auf der eigenen Hardware zu betreiben. Projekte wie LLaMA (Meta), Mistral, Falcon, DeepSeek oder Mixtral sind so optimiert, dass sie auch auf normaler Consumer-Hardware (starke CPU, moderne GPU, ausreichend RAM) lauffähig sind.
Und das Erstaunliche: Manche dieser lokalen Modelle kommen in einzelnen Disziplinen – etwa beim Textverständnis, Programmieren oder in Benchmarks – den großen Cloud-Modellen beeindruckend nahe. Damit eröffnen sich für Forschung, Unternehmen und Privatpersonen völlig neue Möglichkeiten: von Datenschutz und Kostenkontrolle bis hin zu individuellen Anpassungen.
Wir sprechen hier meist von Sprachmodellen, doch aktuelle Systeme können längst viel mehr.
Sie verstehen nicht nur Text, sondern sind in der Lage, auch Bilder, Audio und sogar Video zu verarbeiten und zu erzeugen.Deshalb spricht man heute nicht mehr ausschließlich von Sprachmodellen, sondern von multimodalen Foundation Modellen (kurz MFM).
Diese Modelle verknüpfen verschiedene Eingabe- und Ausgabeformen und eröffnen dadurch völlig neue Anwendungsmöglichkeiten – etwa Bildbeschreibung, Spracherkennung, Code-Generierung oder Videoanalyse.
Auch wenn einige Vorteile vielleicht dafürsprechen, es lokal zu versuchen – welche Nachteile gibt es?
Klar ist: Man benötigt auf jeden Fall leistungsstarke Hardware und ein gewisses Maß an technischem Know-how.
Neuronale Netze#

Sprachmodelle – oder allgemeiner Multimodale Foundation Models (MFM) – basieren auf künstlichen neuronalen Netzen.
Diese sind von der Funktionsweise des Gehirns inspiriert und bestehen aus Millionen künstlicher Neuronen sowie Milliarden von Parametern.
Parameter sind die Gewichte und Bias-Werte, mit denen das Netzwerk während des Trainings Muster erkennt und z.B. Vorhersagen trifft.
Dass hierfür enorme Rechenleistung nötig ist, liegt auf der Hand.
Ein einzelner Prozessor (CPU) stößt hier ganz schnell an seine Grenzen – moderne Grafikkarten (GPUs) sind dagegen bestens geeignet.
Grafikkarten treiben lokale KI an#
Warum? Neuronale Netze benötigen vor allem extrem viele Matrix-Multiplikationen.
Genau diese Art von Berechnungen sind seit jeher das Herzstück der 3D-Grafik:
Schon seit Jahrzehnten nutzen Computerspiele GPUs, um komplexe 3D-Spielwelten in Echtzeit zu berechnen.
Mit dem steigenden Anspruch an Grafikqualität haben sich Grafikkarten zu wahren Rechenmonstern entwickelt.
Heute profitiert die KI davon: Dieselbe Hardware, die für 3D-Spiele gedacht war, eignet sich auch hervorragend für das Training und den Betrieb neuronaler Netze.
(Zudem gibt es heute auch spezialisierte Chips wie TPUs von Google oder die Tensor Cores in NVIDIA-GPUs sowie andere dedizierte AI-Chips, die speziell für KI-Berechnungen entwickelt wurden.)
Wichtiger Faktor: Geschwindigkeit#
Um möglichst viele Matrizen berechnen zu können, braucht es vor allem eine hohe Parallelität.
Das bedeutet: Viele Recheneinheiten („Shaderkerne“) und eine solide Taktfrequenz.
Was sind Shaderkerne?
Shaderkerne sind kleine Recheneinheiten innerhalb der GPU, die ursprünglich für die Berechnung von 3D-Grafik gedacht waren,
- Geometrie zu berechnen (Vertex-Shader)
- Farben und Pixel zu berechnen (Fragment-Shader)
Mit dem Aufkommen von KI kam eine weitere Nutzung hinzu: Compute-Shader.
Dabei handelt es sich um Programme, die auf Shaderkernen laufen und speziell für mathematische Operationen (z. B. Matrixmultiplikationen) entwickelt wurden.
(NVIDIA nennt sie daher CUDA-Kerne)
Im KI-Bereich spricht man deshalb oft von Kernels – hochoptimierten Routinen, die die eigentlichen Berechnungen übernehmen.
Warum ist das wichtig?
- Shaderkerne / CUDA-Kerne sind extrem zahlreich – bei aktuellen Karten wie der RTX 4090 über 16.000 Stück.
- Sie können gleichzeitig (parallel) rechnen, wodurch enorme Geschwindigkeiten erreicht werden.
- Für die Leistung sind daher sowohl die Taktfrequenz als auch vor allem die Anzahl der Kerne entscheidend.
Ausschlaggebend: Speicher#
Noch wichtiger als die reine Rechengeschwindigkeit ist der Speicher – und zwar nicht der Hauptspeicher (RAM), sondern das VRAM (Video RAM) direkt auf der Grafikkarte.
Die Recheneinheiten der GPU (CUDA-/Shaderkerne) können ausschließlich auf diesen Grafikspeicher zugreifen.
Foundation Models sind riesig: Sie enthalten Milliarden von Parametern und benötigen daher enorme Mengen an Speicherplatz. Zusätzlich fällt während der Berechnung weiterer Speicherbedarf für Zwischenergebnisse (z.B. KV-Cache) an.
Das macht den Grafikspeicher zum eigentlichen Flaschenhals.
- Mit 8 GB VRAM lassen sich nur kleine Modelle (z. B. 7B-Modelle in starker Quantisierung) nutzen.
- 16 GB ermöglichen schon komfortableres Arbeiten und den Einsatz mittelgroßer Modelle.
- Ab 24 GB VRAM lassen sich auch größere Sprachmodelle lokal laden und sinnvoll betreiben.
Zwar ist es technisch möglich, den Hauptspeicher (RAM) einzubinden, wenn der VRAM nicht ausreicht – doch dann müssen Daten ständig zwischen Hauptspeicher und VRAM hin- und her kopiert werden.
Das verlangsamt die Berechnungen drastisch und macht eine sinnvolle Nutzung praktisch unmöglich.
Das Modell#
Wir haben nun schon einige Male den Begriff Modell verwendet – aber was genau bedeutet das eigentlich?
Ein Modell ist das Ergebnis des Trainings eines neuronalen Netzes.
Es umfasst:
- die Parameter des Netzes (vor allem Gewichte und Bias-Werte),
- die Architektur des Netzwerks, also die Beschreibung der Schichten und ihrer Verbindungen (oft als Rechengraph dargestellt).
All diese Informationen werden in einer oder mehreren Dateien gespeichert und können später wieder geladen werden.
So wird aus dem trainierten Modell ein Werkzeug, das für die Inferenz – also die praktische Anwendung – genutzt werden kann.
Das sind letztlich die Rohdaten des Modells, die von einer passenden Runtime oder einem Framework geladen und ausgeführt werden können.
Ähnlich wie bei Bildern – die je nach Format (z. B. JPG, PNG, TIFF) unterschiedliche Eigenschaften haben – gibt es auch für Modelle verschiedene Speicherformate.
Nur wenn das richtige Format verwendet wird, kann ein Modell korrekt geladen und für die Inferenz ausgeführt werden.
Sprach- und Foundation-Modelle – wahre Giganten#
Wir haben bereits erwähnt, dass Foundation Models extrem groß sein können. Aber wie groß ist „groß“?
Bei aktuellen Modellen geben die Betreiber – vermutlich aus Konkurrenzgründen – kaum noch Details wie Architektur oder genaue Parameterzahlen preis.
Es gibt jedoch Leaks und fundierte Schätzungen.
Demnach arbeiten diese Netzwerke mit bis zu Billionen von Parametern.
Allerdings werden je nach Architektur (z. B. Mixture of Experts, kurz MoE) nicht alle Parameter gleichzeitig genutzt.
Um Rechenzeit und Speicher zu sparen, werden pro Anfrage („Prompt“) nur bestimmte Experten-Teile des Netzes aktiviert.
Bei GPT-4 bedeutet das nach Schätzungen trotzdem immer noch rund 300 Milliarden aktive Parameter pro Inferenz.
Die Parameter liegen in der Regel als Fließkommazahlen im FP16-Format vor, also 2 Byte pro Parameter (seltener auch als BF16).
Allein das Modell würde damit schon 300 Milliarden × 2 Byte ≈ 600 GB VRAM belegen –
und das ohne zusätzliche Zwischenspeicherungen wie den KV-Cache, der bei langen Kontexten nochmals hunderte Gigabyte beanspruchen kann.
Alles in allem also: riesig und viel zu groß für den lokalen Einsatz.
Deshalb werden für den Betrieb auf normaler Hardware kleinere Modelle entwickelt und optimiert – die aber trotzdem eine erstaunliche Leistung erreichen.
Aktuelle Open-Weight-Modelle für lokale Nutzung#
| Familie / Modell | Verfügbare Größen (Parameter) | Aktiv pro Inferenz | Multimodal? |
|---|---|---|---|
| LLaMA 2 (Meta, 2023) | 7B, 13B, 70B | alle aktiv | Nein |
| LLaMA 3 (Meta, 2024) | 8B, 70B, 405B | alle aktiv | Bild-Funktionen |
| LLaMA 4 (Meta, 2025) | 109B gesamt | 17B aktiv (MoE) | Text + Bild |
| Mistral 7B (2023) | 7.3B | 7.3B | Nein |
| Mixtral 8×7B (2023) | 46.7B gesamt | 12.9B aktiv | Nein |
| Phi-3 (Microsoft, 2024) | 3.8B, 7B, 14B | alle aktiv | Nein |
| Phi-4 (Microsoft, 2025) | 3.8B (Mini), 14B | alle aktiv | Text + Bild |
| Granite Language (IBM, 2024/25) | 3B, 8B, 20B, 34B | alle aktiv | Nein |
| Granite Vision (IBM, 2024/25) | verschiedene Größen | alle aktiv | Text + Bild |
| Falcon (TII, 2023) | 7B, 40B | alle aktiv | Nein |
| Gemma 1 (Google, 2024) | 2B, 7B | alle aktiv | Nein |
| Gemma 2 (Google, 2025) | 9B, 27B | alle aktiv | Nein |
| DeepSeek-V2 (2024) | 236B gesamt | 21B aktiv (MoE) | Nein |
| DeepSeek-V3 (2024/25) | 671B gesamt | 37B aktiv (MoE) | experimentell |
| DeepSeek-R1 Distills (2025) | 1.5B – 70B | alle aktiv | Nein - Reasoning |
Die Größe der Modelle wird meist mit B angegeben – das steht im Englischen für „Billion“ (US-Zählweise) und entspricht Milliarden Parametern auf Deutsch.
Beispiel: LLaMA-3 8B bedeutet, dass das Modell etwa 8 Milliarden Parameter hat.
Die Einheit ist das amerikanische B für „Billion“ (US), was im Deutschen einer Milliarde entspricht.
In der Regel werden die Parameter als 16-Bit-Fließkommazahlen gespeichert – meist im Format FP16 oder BF16.
Das entspricht 2 Bytes pro Parameter.
Rechnen wir kurz: Das kleinste Modell der Reihe, LLaMA-3 8B, hat rund 8 Milliarden Parameter.
Bei FP16/BF16 (16 Bit) entspricht das 2 Byte pro Parameter → 8B × 2 Byte ≈ 16 GB VRAM nur für die Modellgewichte.
Dazu kommt der KV-Cache für die Attention, dessen Größe linear mit der Kontextlänge wächst.
Als “sehr grobe” Faustregel (bei 16 Bit):
- kleine Modelle bis ~10B Parameter → ca. 0,5 MB pro Token
- mittlere Modelle (~10–30B Parameter) → ca. 1 MB pro Token
- große Modelle (70B+) → ca. 3–4 MB pro Token
Praxisbeispiel (8k Kontext):
- 16 GB (Gewichte) + ~4 GB (KV-Cache) + Overhead ⇒ > 20 GB Gesamtbedarf
Selbst eine hochwertige Grafikkarte mit 16 GB VRAM reicht für LLaMA-3 8B in FP16 nicht mehr aus.
Trotzdem zu groß – Speicher weiter reduzieren#
Drücken wir den Speicherbedarf einmal gedanklich herunter:
Modelle werden meist im Format FP16 ausgeliefert.
In FP16 besteht eine Zahl aus:
V EEEEE MMMMMMMMMM
- v = 1 Bit Vorzeichen
- e = 5 Bit Exponent (legt den Wertebereich fest)
- m = 10 Bit Mantisse (legt die Genauigkeit fest)
Damit lässt sich ein Bereich von rund −65.504 bis +65.504 abdecken.
Für viele KI-Modelle sind die Gewichte jedoch bereits auf den Bereich −1 bis +1 normalisiert.
Der große Exponentenbereich wird also kaum genutzt – die 5 Exponenten-Bits sind in diesem Fall überflüssig.
Theoretisch würden also 11 Bit (1+10) genügen, um Modellgewichte in diesem Bereich ohne Präzisionsverlust darzustellen.
Das entspräche einer Ersparnis von rund 31 % Speicher – allerdings nur als Gedankenmodell, da es kein echtes 11-Bit-Format gibt.
Wie kann man diese Modelle doch noch in den Griff bekommen?
Quantisierung - das Wunder der (fast) verlustfreien Komprimierung#
Genau hier setzt Quantisierung an:
Sie reduziert die Bitbreite noch weiter – typischerweise auf 8 Bit oder sogar 4 Bit –
und erzielt dadurch enorme Einsparungen bei Speicher und Rechenaufwand, bei meist nur geringem Qualitätsverlust.
In unseren einfachen Rechnungen konnten wir bereits 5 Bit einsparen, ohne Genauigkeitsverluste.
In der Praxis lässt sich der Wertebereich jedoch nicht immer exakt auf –1 bis +1 begrenzen. Manchmal reicht er weiter, manchmal liegt er nur zwischen –0.2 und +0.2.
Daher arbeitet man nicht mit fixen Grenzen, sondern bestimmt den tatsächlichen Minimal- und Maximalwert der Parameter.
Die so entstehende Range zwischen Min und Max wird anschließend quantisiert, indem man sie in gleichmäßige (lineare) Abstände aufteilt.
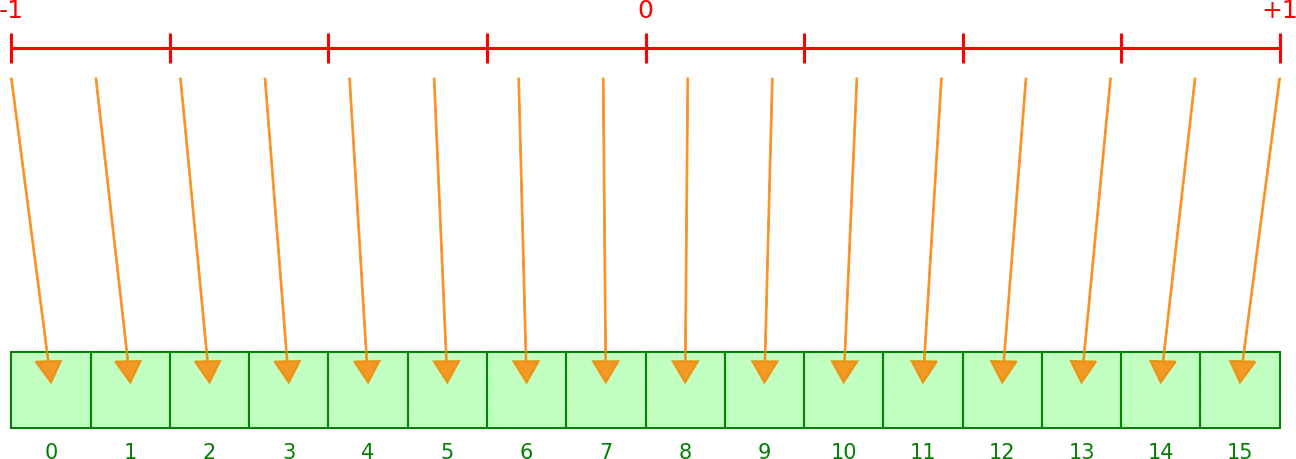
Die Quantisierung wird in Bit angegeben, z. B. 8 Bit, 4 Bit oder sogar nur 2 Bit.
- 8 Bit = 256 Stufen
- 4 Bit = 16 Stufen
- Ganzzahlen: 8 Bit = 1 Byte
Beispiel:
Bei einem Range von –1 bis +1 (Breite = 2.0) und 8 Bit teilen wir diesen Bereich in 256 Stufen auf = 1 Byte
Teilen wir den Wertebereich 2.0 durch 256 Stufen, ergibt sich ein Skalierungswert von 0.0078125.
Das ist der Abstand von einer Stufe zur nächsten und bestimmt die Genauigkeit:
- Weniger Bits → größere Abstände → geringere Genauigkeit.
In der Praxis:
- Für jeden Parameter wird eine Stufe gespeichert (als Byte).
- Zusätzlich gibt es den Skalierungsfaktor.
- Diese Quantisierung passiert nach dem Training, aber vor der Nutzung des Modells.
Symmetrische Quantisierung

- Range ist um 0 symmetrisch (z. B. –1 bis +1).
- Nur ein Skalierungsfaktor wird gespeichert.
- Einfach, aber bei asymmetrischen Daten geht Präzision verloren.
Asymmetrische Quantisierung
- Range ist verschoben (z. B. –1 bis +0.2).
- Zusätzlich zum Skalierungsfaktor wird ein Nullpunkt (Zero Point) gespeichert.
- Der Zero Point legt fest, welche Ganzzahl genau den Wert 0 repräsentiert.
- Vorteil: Der verfügbare Wertebereich wird optimal genutzt.
Dequantisierung#
Bei der Inferenz (Anwendung des Modells) liegen die Parameter nicht mehr als FP16-Werte vor, sondern z. B. nur noch als Ganzzahlenwerte (z. B. 1 Byte pro Gewicht).
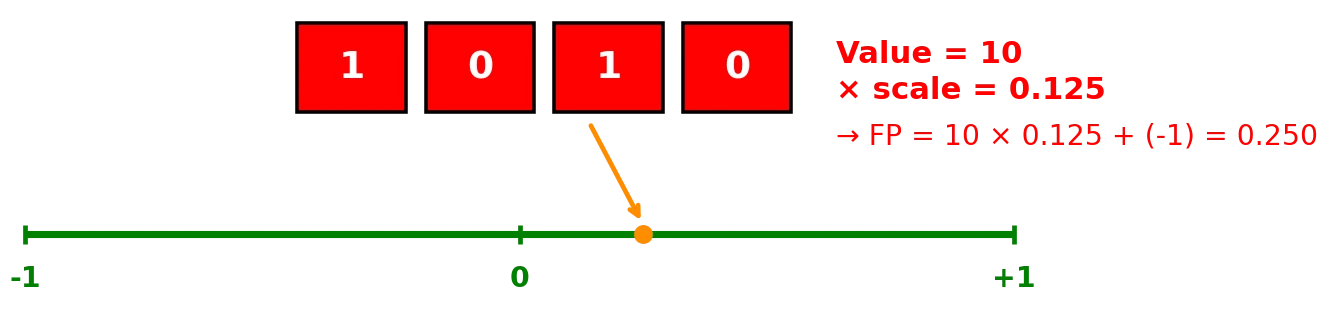
Für die Berechnung müssen diese Ganzzahlen wieder in FP16 konvertiert werden:
Dies geschieht, indem man die Ganzzahl mit dem Skalierungsfaktor multipliziert.
Bei asymmetrischer Quantisierung wird zusätzlich der Nullpunkt (Zero Point) berücksichtigt.
Parameter_fp = (Stufe × Skalierungsfaktor) [+ Nullpunkt bei asymmetrisch]
Durch die Quantisierung können Fehler entstehen, wenn der rekonstruierte Wert vom ursprünglichen Wert abweicht.
Je weniger Bits verwendet werden, desto höher die mögliche Abweichung.
- Mit 8 Bit spart man bereits rund 50 % Speicherplatz, in der Praxis meist mit kaum messbaren Verlusten.
- Mit 4 Bit lassen sich sogar 75 % einsparen, allerdings steigt die Wahrscheinlichkeit von Genauigkeitsverlusten.
Faustregel:
- FP16: Originalpräzision → hohe Qualität, viel Speicherbedarf
- INT8: Standard für Inferenz → kaum Qualitätsverlust, große Ersparnis
- INT4: weitere starke Ersparnis → meist noch gute Qualität (mit spezieller Quantisierung)
- INT2: extreme Kompression → Qualität stark eingeschränkt, oft kaum brauchbar
Bedeutet das nicht großen Rechenaufwand?#
Ja, für jeden Parameter ist eine Multiplikation und ggf. eine Addition (bei asymmetrischer Quantisierung) nötig.
Der VRAM-Gewinn gleicht diesen Mehraufwand aber meist aus.
Außerdem unterstützen moderne GPUs, TPUs und NPUs bereits spezielle Quantisierungs-Operatoren, die diese Schritte sehr effizient ausführen.
Bekommt das ganze Netzwerk die gleiche Skalierung?#
Nicht unbedingt …
In der Praxis teilt man die Parameter oft in Spalten (Channels) oder Gruppen auf und vergibt dafür getrennte Skalierungsfaktoren.
Das verbessert die Genauigkeit deutlich gegenüber einer einzigen globalen Skalierung.
Werden alle Parameter des Modells quantisiert?#
Grundsätzlich ja – aber die größten Einsparungen erzielt man bei den Hauptblöcken:
Attention (Q, K, V, O Projektionen):
Belegen je nach Architektur rund 20–30 % der Parameter.Feed Forward Network (FFN / MLP):
Macht rund 60–70 % der Parameter aus.
Kleinere Teile wie Embeddings oder LayerNorms sind vergleichsweise unbedeutend. Die meisten Einsparungen durch Quantisierung entstehen also im FFN und im Attention-Block.
GPTQ (Gradient Post-Training Quantization)#
GPTQ ist ein Verfahren, das nach dem Training angewendet wird und die Qualität der Quantisierung deutlich verbessert.
Dabei werden die Parameter nicht alle gleich behandelt, sondern nach ihrer Wichtigkeit unterschieden.
Mit Hilfe der Hessian-Matrix (eine Ableitungsmatrix, die Sensitivität und Krümmung beschreibt) wird abgeschätzt, wie stark sich ein Quantisierungsfehler bei einem bestimmten Parameter auf die Modellqualität auswirkt.
So erhalten wichtige Parameter feinere Skalierungen, während weniger wichtige Parameter gröber quantisiert werden können.
Das ermöglicht eine effizientere Kompression, bei gleichzeitig geringerem Qualitätsverlust.
Vorteil: GPTQ erlaubt oft Quantisierungen bis 4 Bit mit nur minimalen Genauigkeitseinbußen, wodurch große Modelle auf deutlich kleineren Geräten lauffähig werden.
Der Player für dein KI-Modell: die Runtime#

Jetzt haben wir den etwas trockenen Teil hinter uns und wissen, worauf es ankommt und worauf wir achten müssen.
Einen passenden Computer mit starker Grafikkarte und ausreichend VRAM haben wir uns bereits besorgt.
Nun geht es in die Praxis: Wie lassen sich multimodale Foundation Models auf Consumer-Hardware nutzen?
Bei Modellen ist es ähnlich wie bei Videos: Mit der Datei allein kann der Computer wenig anfangen – er braucht einen Player, damit etwas passiert.
Was bei Videos der Videoplayer ist, ist bei Foundation Models die LLM-Runtime.
Sie lädt das Modell und bietet uns die Schnittstelle, um damit zu interagieren – zum Beispiel in Form eines Chats.
Wie KI-Software auf die Grafikkarte zugreift#
Der Zugriff einer Runtime – oder allgemein von KI-Software – auf die GPU erfolgt in mehreren Ebenen.

Unterste Ebene: die eigentliche Hardware (GPU).
Dafür stellt der jeweilige Hersteller passende Treiber bereit.
Diese Treiber sind nötig, damit das Betriebssystem und die Software überhaupt mit der GPU kommunizieren können.Darüber: der Zugriff auf die Hardware geschieht über eine Programmierschnittstelle (API).
Diese kann entweder- herstellerspezifisch sein (z. B. CUDA von NVIDIA)
- oder auf einem offenen Standard basieren (z. B. DirectML)
Diese Schnittstellen bilden die Grundlage, auf der KI-Frameworks wie PyTorch, TensorFlow oder KI Applikationen arbeiten.
Herstellerspezifische Schnittstellen#
Diese Schnittstellen sind speziell für eine bestimmte Hardware-Familie optimiert (z. B. nur für NVIDIA).
Sie funktionieren ausschließlich auf den GPUs dieses Herstellers.
Vorteil:
Die besonderen Fähigkeiten und Funktionen der Hardware können gezielt und sehr performant genutzt werden.Nachteil:
Für jede andere Hardware-Familie muss separat programmiert werden – ein Wechsel des Herstellers ist damit schwierig.
Beispiele:
- NVIDIA: CUDA
- AMD: ROCm
- Intel: oneAPI
- Apple: Metal (MPS)
Universelle Schnittstellen#
Hier stellen Konsortien oder Standardisierungsorganisationen eine gemeinsame Schnittstelle bereit, die auf Hardware vieler Hersteller lauffähig ist.
Vorteil:
Eine Schnittstelle funktioniert mit GPUs verschiedener Anbieter – weniger Abhängigkeit vom Hersteller.Nachteil:
Spezielle Funktionen einzelner GPUs können nicht ausgereizt werden, außerdem ist der Zugriff in der Regel etwas langsamer.
Beispiele:
- OpenCL: – Khronos Group
- Vulkan Compute: – Khronos Group
- DirectML: – Microsoft
Runtimes für lokale und skalierte Nutzung#
Für die verschiedenen Betriebssysteme – Linux, Windows und macOS – stehen unterschiedliche Runtimes zur Verfügung.
Aktuell sind Linux-Nutzer etwas im Vorteil, da viele Tools zuerst für Linux entwickelt und optimiert werden.
Unter Windows lassen sich viele davon jedoch ebenfalls nutzen, z. B. über das Windows Subsystem for Linux (WSL).
Auch macOS wird inzwischen gut unterstützt, insbesondere seit es Apple Silicon (M1/M2/M3) mit eigener GPU-Beschleunigung gibt.
Wichtig ist die Unterscheidung nach dem Einsatzzweck:
- Lokale Runtimes für Einzelrechner (z. B. llama.cpp)
- Server- oder Cluster-Runtimes für skalierte Nutzung (z. B. vLLM)
Lokale Runtimes#
Eine lokale Runtime ist in der Regel schnell installiert und eingerichtet.
Sie ist für den Betrieb auf einem einzelnen Rechner gedacht und eignet sich besonders für kleinere Workflows, die direkt auf dieser Maschine laufen oder sich gezielt mit genau diesem Rechner verbinden.
Typische Vertreter:
- llama.cpp – leichtgewichtig, sehr portabel, läuft auf fast allen Plattformen
- Ollama – CLI-/API-orientiert, einfach in eigene Anwendungen integrierbar
- LM Studio – benutzerfreundliche Desktop-App mit GUI und Modellverwaltung
Server- oder Cluster-Runtimes (Inference Engines)#
Diese Runtimes sind deutlich komplexer in der Installation und richten sich an professionelle Anwendungen mit vielen gleichzeitigen Anfragen.
Sie sind für den Einsatz auf leistungsstarker Server-Hardware gedacht, oft mit mehreren GPUs, und lassen sich sehr gut skalieren – von einzelnen Servern bis hin zu großen Clustern.
Typischerweise werden dafür Datacenter-GPUs wie die NVIDIA A100 oder H100 genutzt.
Typische Vertreter:
- vLLM (UC Berkeley) – hochoptimierte Inference Engine, u. a. mit PagedAttention
- Text Generation Inference (TGI, Hugging Face) – Serving-Framework für Produktionsumgebungen
- TensorRT-LLM (NVIDIA) – maximal optimierte Inferenz auf NVIDIA-GPUs mit Tensor Cores
Für kleinere Anwendungen bieten sich lokale Runtimes an#
Grundsätzlich brauchen wir einen Motor unter der Haube, der Modelle laden und ausführen kann.
Bei den lokalen Runtimes kommt sehr häufig llama.cpp zum Einsatz.
llama.cpp#
llama.cpp ist eine extrem schnelle, hardwarenahe Bibliothek, die in C/C++ mit teils Assembler-Optimierungen entwickelt wurde.
Sie ermöglicht es, große Sprachmodelle effizient auch auf Consumer-Hardware laufen zu lassen.
- Bietet Bindings für viele Programmiersprachen (z. B. Python, Go, Rust), sodass andere KI-Programme unter verschiedenen Betriebssystemen die Funktionen der Bibliothek nutzen können.
- Dieser Zugriff erfolgt über eine API (Application Programming Interface).
- Zusätzlich gibt es ein Command Line Interface (CLI), über das man direkt mit der Bibliothek arbeiten kann.
llama.cpp kann GGUF-Modelle (Generalized GGML Unified Format) laden und ausführen – auch in quantisierter Form, um Speicher und Rechenleistung zu sparen.
Da die direkte Nutzung von llama.cpp eher technisch und für Entwickler gedacht ist, greifen viele Nutzer auf eine höhere Abstraktionsebene zurück – also auf Runtimes oder Tools, die auf llama.cpp aufbauen und eine benutzerfreundlichere Oberfläche bieten.
LM Studio#
LM Studio ist eine komfortable Runtime mit klarer GUI-Ausrichtung und richtet sich vor allem an Endanwender.
Es bietet eine integrierte Modell-Liste („Model Catalog“), über die man Modelle direkt auswählen und herunterladen kann.
Inzwischen legt das Projekt auch mehr Fokus auf Entwickler:
- Es gibt ein eigenes Command Line Tool (
lms), mit dem sich Modelle laden, verwalten und der API-Server steuern lassen. - Zusätzlich stellt LM Studio eine OpenAI-kompatible REST-Schnittstelle bereit, sodass es problemlos von anderen Programmen angesteuert werden kann.
Unterstützte Formate:
- GGUF (Standard für llama.cpp-basierte Runtimes)
- MLX (speziell für Apple über die MLX-Schnittstelle)
Basis: LM Studio baut intern auf llama.cpp auf, erweitert dies aber um GUI, API und Komfortfunktionen.
🔗 LM Studio Website
🔗 LM Studio Model Catalog
Ollama#
Ollama ist stärker auf Developer ausgerichtet und bietet umfangreiche Steuerungsmöglichkeiten:
- Command Line Interface (CLI) für direkte Kontrolle
- OpenAI-kompatible REST-API für die Integration in eigene Anwendungen
- SDKs (z. B. für Python, JavaScript), um Ollama von außen programmatisch zu steuern
Inzwischen richtet sich Ollama aber auch zunehmend an Endanwender – dafür gibt es z. B. einen integrierten UI-Chat-Client.
Basis: Auch Ollama nutzt unter der Haube llama.cpp als Runtime.
Unterstützte Formate:
- Eigenes Ollama-Format (
Modelfile), vergleichbar mit einem Dockerfile für Modelle. - GGUF (Standard für llama.cpp-basierte Runtimes) – kann in ein Ollama-Format „importiert“ werden.
- PyTorch (.pt / .pth) – nach Konvertierung.
- Safetensors (.safetensors) – nach Konvertierung.
Modellbibliothek:
Ollama stellt eine eigene offizielle Modellbibliothek bereit, aus der Modelle direkt per CLI heruntergeladen und gestartet werden können:
🔗 Ollama Website
🔗 Ollama GitHub
Was ist eigentlich …
- API (Application Programming Interface):
Schnittstelle, über die Programme Funktionen einer Bibliothek aufrufen können. - Library (Bibliothek):
Sammlung von wiederverwendbaren Funktionen, die in eigenen Programmen genutzt werden können. - SDK (Software Development Kit):
Werkzeugkasten für Entwickler, der eine Bibliothek, Dokumentation, Beispiele und Tools enthält. - REST API:
Eine Web-API, die über das HTTP-Protokoll funktioniert und nach REST-Schema aufgebaut ist. Wird genutzt um Dienste über das Netzwerk anzusprechen.
Gängige Formate für Foundation Models#
| Format / Suffix | Firma/Organisation | Kurzbeschreibung | Typische Anwendung |
|---|---|---|---|
| PyTorch (.pt, .pth, .bin, .safetensors) | Meta / Open-Source | Standard für Training | Viele Open-Source-Modelle |
| GGUF / GGML (.gguf, .ggml) | Community (llama.cpp) | Optimiert für lokale Nutzung | Ollama, LM Studio, llama.cpp |
| ONNX (.onnx) | Microsoft / Open-Source | Austauschformat | Deployment auf Servern/Edge |
| TensorRT (.engine) | NVIDIA | GPU-optimiertes Format | Inferenz auf NVIDIA-GPUs |
| CoreML (.mlmodel) | Apple | Apple-spezifisches Format | KI auf iPhone, iPad, Mac |
Welche Runtime passt am besten?#
Die drei Runtimes unterscheiden sich zunehmend weniger in ihrem Funktionsumfang.
Am Ende ist es vor allem eine Frage der persönlichen Vorlieben:
- Wie schnell möchte ich starten?
- Wie viel Zeit und Energie will ich in Konfiguration und Feinschliff investieren?
Im nächsten Abschnitt werfen wir einen praktischen Blick auf die Ollama Runtime.
Ollama in der Praxis#
In diesem Tutorial zeige ich dir die Installation und Nutzung von Ollama unter Windows.
Ollama herunterladen#
Rufe die offizielle Download-Seite auf:
Dort wählst du dein Betriebssystem aus.

Installation#
Nachdem der Download abgeschlossen ist, startest du die Installation.
- Standardinstallation (Ollama wird in den Standardordner installiert):
OllamaSetup.exe
- Eigener Installationspfad (Beispiel):
OllamaSetup.exe /DIR="D:\Dein\Pfad"
Ollama starten#
Die Installation ist abgeschlossen – jetzt können wir Ollama starten.
Da Ollama Command-Line-first ist, öffnen wir eine Eingabeaufforderung oder PowerShell und starten es dort:

Architektur von Ollama#
Ollama hat einen hierarchischen Aufbau:
- Es basiert auf llama.cpp
- Beim Start öffnet es einen Port unter
http://localhost:11434 - Darüber stellt es eine OpenAPI-kompatible REST-API bereit

Auf dieser Grundlage können verschiedene Clients mit Ollama kommunizieren – zum Beispiel:
- die Kommandozeile
- die Chat-Oberfläche
- externe AI-Programme oder Skripte
Ollama Modell laden#
Nachdem Ollama läuft, wollen wir natürlich ein Modell starten, mit dem wir chatten können.
Modelle finden
Eine Übersicht verfügbarer Modelle findest du in der Ollama Library:
https://ollama.com/library
Modell herunterladen
Hast du ein Modell gefunden, kannst du es mit ollama pull in dein lokales Modellverzeichnis laden.
Beispiel:
ollama pull llama3.2-vision:11b-instruct-q4_K_M

Modell starten
Um mit dem Modell zu chatten, starten wir es mit ollama run:
ollama run llama3.2-vision:11b-instruct-q4_K_M

In diesem Beispiel verwende ich ein multimodales Vision-/Text-Modell (4-Bit quantisiert).
Das bedeutet: es kann sowohl Texteingaben als auch Bilder verarbeiten. Und obwohl es sich um ein sehr kleines, hochquantisiertes Modell handelt – und als Text-Vision-Modell im reinen Textverständnis nicht ganz so stark ist – liefert es bereits in deutscher Sprache beeindruckend gute Antworten.
Laufzeit-Parameter
Beim Start lassen sich zusätzliche Optionen setzen, um das Verhalten des Modells zu steuern.
Beispiel:
ollama run granite3.2-vision:latest -o temperature=0.2 -o num_ctx=4096
Hiermit werden die Parameter temperature und Kontextlänge (num_ctx) überschrieben.
Nützliche Befehle zur Modellverwaltung
ollama list→ installierte Modelle auflistenollama show <modell>→ Infos & Fähigkeiten eines Modells anzeigenollama pull <modell>→ Modell herunterladenollama push <modell>→ Modell hochladenollama create <modell>→ neues Modell anlegenollama cp <quelle> <ziel>→ Modell kopierenollama rm <modell>→ Modell löschen
Runtime-Befehle von Ollama
Neben den Modell-Management-Befehlen gibt es auch Runtime-Befehle, mit denen laufende Modelle gesteuert werden können:
ollama stop <modell>→ laufendes Modell stoppenollama ps→ aktuell laufende Modelle auflistenollama serve→ Ollama-Server ohne Modell starten
Modellquellen & Vertrauenswürdigkeit
Alle registrierten Modelle findest du hier:
https://ollama.com/library
Wichtig: Eine „echte“ zentrale Qualitätskontrolle gibt es nicht. Ollama ist eher ein Community-getriebenes Projekt.
Daher solltest du beim Download darauf achten, dass die Modelle von seriösen Uploadern stammen (z. B. direkt von Ollama selbst) und ein Modell validieren, bevor du es produktiv einsetzt.
Herkunft der Modelle#
Viele Modelle werden von den Anbietern (Vendors) zunächst auf Hugging Face veröffentlicht:
https://huggingface.co/
Erst danach werden sie von der Community in die Ollama-Bibliothek übernommen.
Daher kann es manchmal etwas dauern, bis neue Modelle auch über Ollama verfügbar sind.
Modelle anpassen (Customizing)#
Ollama erlaubt es, ein Modell zu customizen, sodass bestimmte Parameter oder Systemeinstellungen direkt ins Modell „eingebrannt“ werden.
Beispiel:
PARAMETER temperature 0.2
SYSTEM "Du bist ein hilfsbereiter Assistent"
Damit kannst du z. B. die Temperatur dauerhaft setzen oder ein globales System-Prompt definieren.
OpenAI-kompatible REST-API#
Ollama bietet eine OpenAI-kompatible REST-API, über die sich Anfragen senden lassen – z. B. mit curl oder in einem Python-Skript.
Diese API hat sich inzwischen faktisch als Standard-Schnittstelle etabliert, um verschiedenste Sprach- und Foundation-Modelle anzusprechen.
Das bedeutet: Viele vorhandene Tools und Bibliotheken, die eigentlich für die OpenAI-API gedacht sind, lassen sich direkt mit Ollama nutzen.
API-Nutzung mit curl
Über die REST-API von Ollama lassen sich Modelle direkt ansprechen – zum Beispiel mit curl:
curl http://localhost:11434/v1/chat/completions -H "Content-Type: application/json" -H "Authorization: Bearer ollama" -d "{\"model\":\"llama3.2-vision:11b-instruct-q4_K_M\",\"messages\":[{\"role\":\"user\",\"content\":\"Welche Stadt ist die Landeshauptstadt von Vorarlberg?\"}]}"
API-Nutzung mit python
#pip install openai
from openai import OpenAI
client = OpenAI(
api_key="dummy",
base_url="http://localhost:11434/v1"
)
resp = client.chat.completions.create(
model="llama3.2-vision:11b-instruct-q4_K_M",
messages=[{"role": "user", "content": "Welche Stadt ist die Landeshauptstadt von Vorarlberg?"}]
)
print(resp.choices[0].message.content)
... und wir erhalten jeweils das richige Ergebnis als json reponse: Bregenz
Environment-Variablen in Ollama#
Ollama unterstützt verschiedene Environment-Variablen, mit denen sich Verhalten und Speicherorte anpassen lassen.
Hier eine kleine Auswahl (die vollständige Liste findest du in der offiziellen Dokumentation):
OLLAMA_HOST→ Server-Adresse & Port festlegen (z. B.127.0.0.1:0815)OLLAMA_MODELS→ Speicherort für Modell-Dateien überschreibenOLLAMA_DEBUG→ auf1setzen, um zusätzliche Debug-Ausgaben zu aktivieren
Damit kannst du Ollama an deine lokale Umgebung und Workflows anpassen.
Dokumentation#
Ollama ist gut dokumentiert – mit vielen Beispielen und Code-Snippets.
https://ollama.readthedocs.io/en/
Ollama GUI#
Obwohl Ollama ursprünglich Command-Line-first entwickelt wurde, gibt es mittlerweile auch eine grafische Benutzeroberfläche (GUI).
Du kannst das GUI mit folgendem Befehl starten:
"ollama app.exe"
Frage im GUI: „Welche Stadt ist die Landeshauptstadt von Vorarlberg?“

Wenn du ein multimodales Modell (z. B. llama3.2-vision) verwendest, kannst du im GUI nicht nur Texteingaben machen, sondern auch Bilder hochladen.
So kannst du direkt Fragen zu einem Bild stellen – das Modell kombiniert dann Text- und Bildinformationen in seiner Antwort.

Nachdem wir ein Bild hochgeladen und eine Frage gestellt haben, liefert uns das multimodale Modell die passende Antwort.

Ollama im System-Tray#
Neben der Kommandozeile und dem GUI ist Ollama nach der Installation auch im System-Tray verfügbar (Taskleiste unten rechts in Windows).

Einstellungen in Ollama#
Über die Einstellungen in der Ollama-App lassen sich verschiedene Optionen anpassen.
Besonders interessant sind dabei:
- Model Location → legt fest, in welchem Verzeichnis die Modelle gespeichert werden.
- Context Length → bestimmt die Länge des Kontextfensters.
- Je größer das Kontextfenster, desto mehr Text (oder Bildinformationen) kann das Modell gleichzeitig berücksichtigen.
- ⚠️ Achtung: Ein größeres Kontextfenster benötigt auch mehr Grafikspeicher (VRAM).
Fazit#
Lokale Foundation-Modelle sind längst kein Spielzeug mehr. Mit der richtigen Hardware und Runtime lassen sie sich heute effizient einsetzen – privat wie auch im Unternehmen. Sie bringen Datenschutz, Kontrolle und Kostenersparnis, erfordern aber auch technisches Know-how und klare Verantwortung.
© 2025 Oskar Kohler. Alle Rechte vorbehalten.Hinweis: Der Text wurde manuell vom Autor verfasst. Stilistische Optimierungen, Übersetzungen sowie einzelne Tabellen, Diagramme und Abbildungen wurden mit Unterstützung von KI-Tools vorgenommen.