
ChatGPT ist auch nur ein neuronales Netzwerk …#
LLMs (Large Language Models) wie ChatGPT – und generative KI (künstliche Intelligenz) im Allgemeinen – haben einen regelrechten Hype ausgelöst. Meiner Meinung nach: völlig zurecht! Für mich ist ChatGPT das achte Weltwunder – vielleicht etwas dramatisch formuliert. Aber wer schon länger damit arbeitet, weiß, was ich meine.
Obwohl ich mich seit Jahren mit KI beschäftige, hätte ich mit dieser steilen Entwicklung in so kurzer Zeit niemals gerechnet. Die allwissende KI-Assistentin, die man früher nur aus Science-Fiction-Filmen kannte, ist plötzlich Realität geworden. Sie sitzt heute direkt vor uns – wir können mit ihr chatten, sprechen und sie um Rat bei unseren alltäglichen Problemen bitten.
Viele nutzen KI-Assistenten inzwischen täglich – aber wie funktionieren diese Wunderwerke eigentlich? Wo liegen ihre Stärken, wo ihre Schwächen? Genau diesen Fragen gehe ich in diesem Artikel auf den Grund.
Doch bevor wir uns anschauen, was unter der Haube von LLMs wie ChatGPT vor sich geht, brauchen wir ein grundlegendes Verständnis von neuronalen Netzwerken. Denn wie alle modernen KI-Wunder basiert auch ChatGPT – und vergleichbare Systeme – auf Deep Learning, dessen Grundlage künstliche neuronale Netzwerke sind.
Programmieren vs Lernen#
Computerprogramme wie MS Office®, Acrobat Reader®, Photoshop® oder auch Webseiten werden klassisch “von Hand” in einer Programmiersprache entwickelt – und schlussendlich in eine Sprache übersetzt die der Computer versteht: Maschinensprache – die einzige Sprache, die ein Prozessor direkt verarbeitet.
Klassische Programme verwenden Algorithmen, Variablen und Kontrollstrukturen wie Schleifen und Bedingungen. Sie funktionieren deterministisch – dieselbe Eingabe führt immer zur selben Ausgabe. Sie arbeiten unermüdlich, aber ohne dazuzulernen. Ein Software-Automat ohne “Gehirn”.
Unser Gehirn als Inspiration#
Schon in der 1950er Jahren, also vor mehr als 70 Jahren, hatte die Wissenschaft eine konkrete Vorstellung wie unser Gehirn ungefähr funktioniert. Daraufhin wurde die erste künstliche “Gehirnzelle” konstruiert: das Perzeptron. Es konnte einfache Signale verarbeiten und war sogar lernfähig – hatte allerdings noch Schwierigkeiten mit komplexeren logischen Aufgaben.
Vom Perzeptron zum künstlichen Neuron#
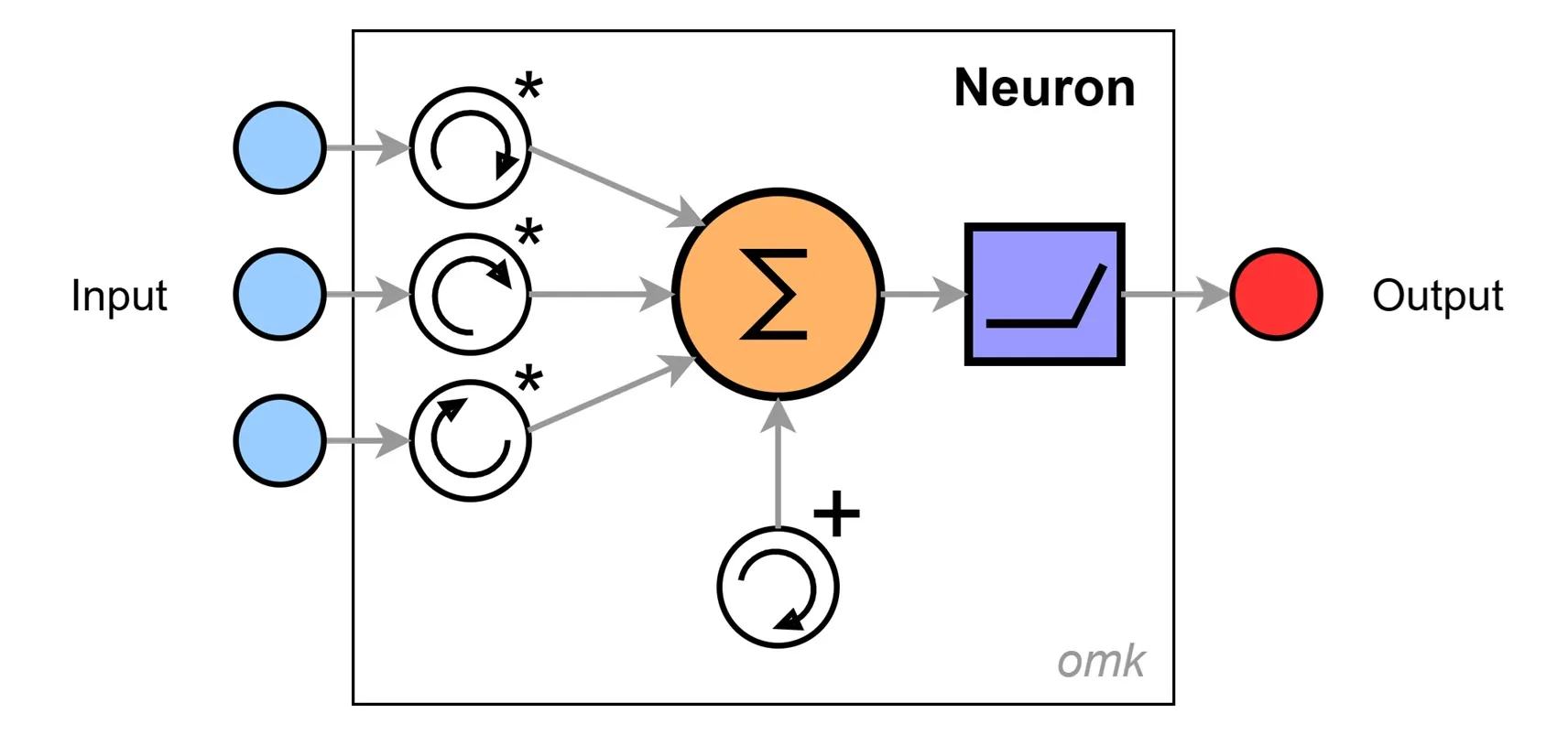
Das künstliche Neuron ist eine vereinfachte Darstellung eines Neurons aus unserem Gehirn. Eine kleine Blackbox, in der verschiedene Eingangssignale zu einem Ausgangssignal verarbeitet werden.
Die einzelnen Eingänge sind gewichtet – das heißt, ihre Signale werden je nach Bedeutung verstärkt oder abgeschwächt. Anschließend werden sie zu einer Gesamtsumme aufaddiert, und ein Schwellwert – das sogenannte Bias – wird hinzu addiert. Mit dem Bias lässt sich der Gesamtpegel heben oder senken. Alle Parameter wie Gewichte und Bias sind anpassbar – dadurch wird das Neuron lernfähig.
Fertig ist unser lernfähiges Rechenwerk – und das überraschend einfach.
Aktivierung bringt Logik ins Spiel#
Damit neuronale Netze auch komplexere logische Probleme lösen können, benötigt es eine geeignete Aktivierungsfunktion. Sie entscheidet, ob und wie ein Signal im Netzwerk weitergeben wird – quasi ein neuronaler Schalter oder Daten-Router.
Früher wurden verschiedene Aktivierungsfunktionen wie Sigmoid, Tanh oder Softsign eingesetzt.
Heute nutzt man meist nur noch 2 Hauptfunktionen:
- ReLU (Rectified Linear Unit) zur Merkmalsextraktion ➔ für Mustererkennung
- Softmax zur Klassifizierung ➔ Ausgabe einer Wahrscheinlichkeitsverteilung
Lernen einfach gemacht#
- Die Eingangssignale sollen zu einem definierten Ausgangssignal führen.
- Weicht das Ergebnis ab, drehen wir an den Reglern: an den Gewichten, um Signale zu verstärken oder zu unterdrücken – und zusätzlich am Bias um das Gesamtsignal anzuheben oder abzusenken.
- So lange - bis wir mit dem Ergebnis zufrieden sind …
👉 Hier kannst du mit Eingaben, Gewichten, Bias und Aktivierung experimentieren – und sehen, was am Ende rauskommt.#
Eine Gehirnzelle macht noch kein Gehirn#
Ein menschliches Gehirn besteht aus etwa 86.000.000.000 (86 Milliarden!) Neuronen – auch wenn man das bei manchen Personen vielleicht nicht erwarten würde :-). Eine unüberschaubare Anzahl kleiner „Rechner“ und „Schalter“, komplex und eng miteinander vernetzt. Ihre Verbindungen verlaufen kreuz und quer durch das Gehirn und nehmen sogar den größten Teil des Gehirnvolumens ein. Erst dieses weitreichende Netzwerk ermöglicht die beeindruckenden kognitiven Fähigkeiten des Menschen.
Und genauso besteht auch ein künstliches neuronales Netz nicht nur aus einem Neuron, sondern aus einer großen Anzahl eng verbundener Neuronen.
Die Leistungen solcher Netzwerke sind faszinierend. Es muss nicht gleich ChatGPT mit Milliarden von Parametern sein – selbst mit einer Handvoll Neuronen lassen sich erstaunlich komplexe Probleme lösen.
Neuronale Netze – Profis der Mustererkennung#
Eine Fähigkeit, die neuronale Netze - insbesondere tiefe neuronale Netze – beeindruckend gut beherrschen, ist das Erkennen von Mustern in Daten.
- ChatGPT® erkennt Muster in Texten
- Dall-E® erkennt Muster in Bildern
- Sora® erkennt Muster in Videos
- Whisper® erkennt Muster in Audiodateien
In genau dieser Disziplin ist KI uns Menschen inzwischen haushoch überlegen - und diese Fähigkeit bildet das Fundament vieler aktueller KI-Tools und des aktuellen KI-Hypes.
Handgeschriebene Ziffern erkennen - mit nur 34 Neuronen#
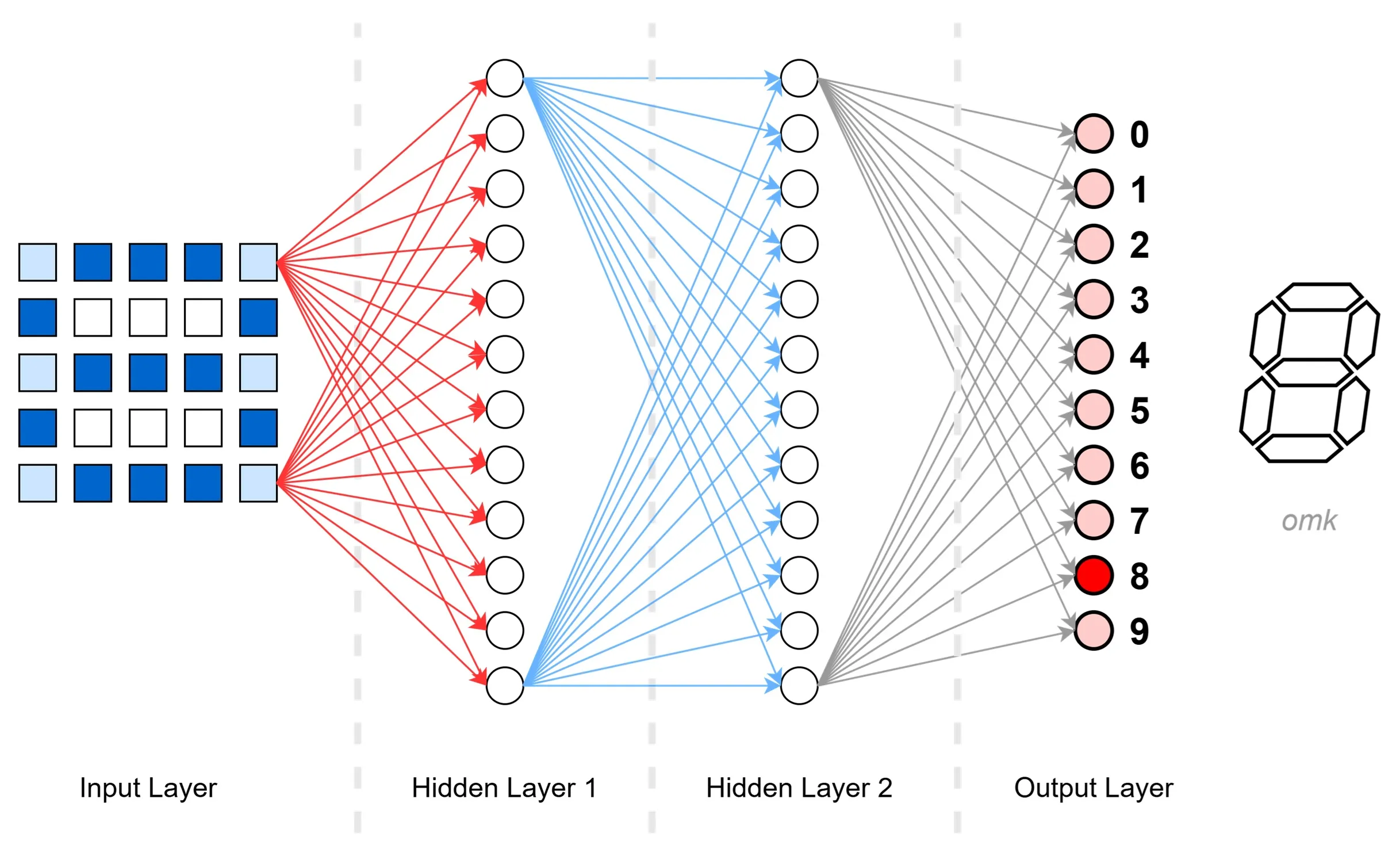
Ein simples neuronales Netz – mit gerade einmal 34 Neuronen – kann recht zuverlässig handgeschriebene Ziffern erkennen.
Dieser Netzwerktyp wird als FFN (Feed-Forward Network) oder FCN (Fully Connected Network) bezeichnet. Es ist der am häufigsten verwendete Typ neuronaler Netze. Dabei ist Jedes Neuron einer Schicht mit allen Neuronen der nächsten Schicht verbunden. Die Signale fließen dabei stets in eine Richtung: vorwärts – ohne Rückkopplungen.
Wie funktioniert das?!#
Input Layer – der Start#
Mithilfe eines Scanners digitalisieren wir eine einzelne Ziffer in eine 5*5-Matrix – also 25 Bildpunkte in unterschiedlichen Graustufen, von hell bis dunkel. Je dunkler der Punkt, desto stärker das Signal. Alle 25 Bildpunkte sind mit sämtlichen Neuronen der nächsten Schicht – dem Hidden Layer 1 – verbunden.
(Zur besseren Übersicht zeigt das Bild nur zwei verbundene Bildpunkte. In Wirklichkeit ist jedes Neuron einer Schicht mit allen Neuronen der nächsten Schicht verbunden – typisch für ein voll verbundenes Netzwerk.)
Hidden Layer 1 – Erste Merkmale extrahieren#
Die Neuronen in dieser Schicht verarbeiten nun die Eingangssignale. Ihr Ziel: Merkmale erkennen, die auf eine bestimmte Ziffer hinweisen. Jeder Rechenschritt folgt demselben Schema:
- Gewichtetes Multiplizieren: Jedes Eingangssignal wird mit seinem zugehörigen Gewicht multipliziert.
- Aufsummieren der Signale: Alle gewichteten Signale werden zu einer Gesamtsumme ∑ addiert.
- Bias hinzufügen: Ein Bias-Wert wird addiert, um den Signalpegel zu justieren.
- Aktivieren mit ReLU: Die ReLU-Funktion entscheidet, ob und wie stark das Signal an die nächste Schicht weitergegeben wird.
Auch dieser Layer ist wieder vollständig mit der nächsten Schicht verbunden.
Hidden Layer 2 – Weitere Merkmale extrahieren#
In dieser Schicht passiert technisch dasselbe wie bereits im Hidden Layer 1: Die Eingangsdaten werden erneut verarbeitet, wobei nun weitere – und meist abstraktere – Merkmale erkannt werden. Anschließend werden die Signale mithilfe der Aktivierungsfunktion an die Zielschicht weitergegeben: den Output Layer.
Output Layer – die Entscheidung#
Diese Schicht trifft nun die finale Entscheidung: Welche Ziffer wurde geschrieben? Basierend auf den zuvor extrahierten Merkmalen wählt das Netzwerk die wahrscheinlichste Ziffer aus.
Dazu verwenden wir diesmal nicht die ReLU-Aktivierungsfunktion – die ist für das Erkennen von Merkmalen zuständig. Stattdessen kommt jetzt die Softmax-Funktion zum Einsatz: eine Klassifizierungsfunktion, die für jede mögliche Ziffer eine Wahrscheinlichkeit ausgibt.
In unserem Beispiel erkennt das Netzwerk die Ziffer mit der höchsten Wahrscheinlichkeit – eine 8.
Wo und wie genau wurde nun die Ziffer erkannt?#
Die erstaunliche Antwort: Man weiß es nicht so genau!
Das Netzwerk erkennt die Ziffern auf Basis selbst gelernter, abstrakter Merkmale – ohne dass wir genau nachvollziehen können – was es da eigentlich erkannt hat. Für uns Menschen ist das schwer greifbar: Es gibt keine klar formulierten Regeln wie: “Eine 8 besteht aus 2 übereinander liegenden Kreisen”.
Stattdessen entdeckt jede Schicht im Netzwerk seine eigenen Muster in den Daten. Je tiefer die Schicht, desto abstrakter werden diese Merkmale.
- Die erste Schicht erkennt z.B. einfache Punkte und Linien
- Die zweite Schicht erkennt Ecken, Bögen oder Fragmente
- Weitere Schichten kombinieren diese Informationen zu komplexeren Strukturen
Das Problem der Erklärbarkeit und Nachvollziehbarkeit#
Es ist schwer zu sagen, warum das Netzwerk entscheidet, dass eine bestimmte Eingabe nicht die Ziffer 3 ist – oder welches Neuron genau weshalb aktiviert wurde.
Zwar gibt es Methoden, die Aktivität einzelner Neuronen zu visualisieren, doch gerade bei großen Netzwerken stößt man schnell an Grenzen. Die Erklärbarkeit und Nachvollziehbarkeit der Ergebnisse bleibt eine der größten Herausforderung moderner KI.
Problemfall: Keine Ziffer erkannt#
Was passiert, wenn die Eingabe gar keine Ziffer enthält – z.B. einen Buchstaben?
Viele Netzwerke verfügen über keine eigene Klasse wie “keine Ziffer”. Stattdessen gibt das Modell Wahrscheinlichkeiten für bekannte Klassen aus – auch wenn eigentlich nichts Passendes dabei ist. Das Ergebnis: Mehrere Ziffern erhalten ähnliche Wahrscheinlichkeiten, das Modell ist sich unsicher – und zeigt meist einfach die am wahrscheinlichsten scheinende, aber falsche Ziffer an.
Inferenz – Das Modell nutzen#

Unsere „Ziffern-Erkennungsmaschine“ ist ein bereits trainiertes neuronales Netzwerk – ein sogenanntes Modell. Die Anwendung eines solchen Modells nennt man Inference.
Nach dem Training bleibt das Modell statisch – es passt sich während der Nutzung nicht mehr an.
Die Inference – also das Erkennen der Ziffern – ist technisch gesehen ein vergleichsweise einfacher Prozess: Die Verarbeitung erfolgt schnell und benötigt nur wenig Rechenleistung.
Deutlich aufwendiger ist hingegen das Trainieren eines neuronalen Netzwerks – also der eigentliche Lernvorgang, bei dem das Modell lernt, Muster zuverlässig zu erkennen.
Modell trainieren ➔ Aufwendig und teuer#
Das Ziel eines neuronalen Netzwerks ist meist, komplexe Muster in Daten zu erkennen – etwa Texte in Bildern, Sprache in Audiodateien oder die Unterscheidung von Katzen und Hunden auf Fotos.
Doch das kann ein Netzwerk nicht von selbst. Wir müssen es erst trainieren – also beibringen, wie eine Ziffer aussieht, oder was einen Hund von einer Katze unterscheidet.
Die (eigentlich) einfache Lösung#
Wir zeigen dem Netzwerk viele unterschiedliche Beispiele – und bewerten anschließend das Ergebnis: Hat das Netzwerk das Muster korrekt erkannt?
Weicht das Resultat vom Erwarteten ab, drehen wir an den Reglern: Wir passen die Eingangsgewichte und das Bias an – und zwar für jedes einzelne Neuron.
In den 1950er-Jahren wurde das tatsächlich noch von Hand erledigt – eine Menge Arbeit, aber die Netzwerke waren damals auch noch recht klein. Das blieb jahrzehntelang so – bis schlaue Köpfe in den 1980er-Jahren auf die geniale Idee kamen, den Vorgang zu automatisieren.
Backpropagation – Jetzt KI lernt automatisch#
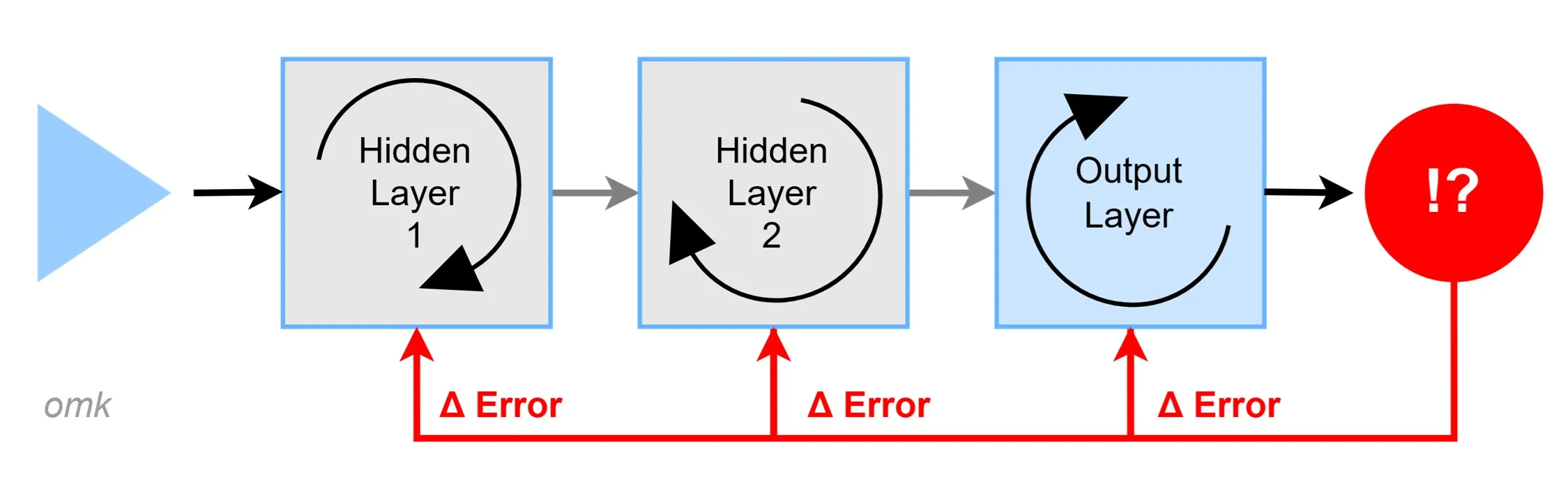
Die Grundidee#
Damit ein neuronales Netz lernen kann, muss es wissen, wie gut es gearbeitet hat. Dazu wird das vom Netzwerk berechnete Ergebnis mit dem erwarteten Ergebnis verglichen. Aus diesem Unterschied berechnet man ein Fehlermaß, den sogenannten Loss.
Je größer der Unterschied, desto größer der Fehler – und damit auch der Korrekturbedarf.
Fehlerverteilung und Justierung#
Da viele Neuronen am Ergebnis beteiligt sind, wird der Fehler mithilfe der Backpropagation rückwärts durch das gesamte Netzwerk verteilt. Für jedes einzelne Neuron wird berechnet, wie stark seine Gewichte und Bias zum Gesamtfehler beigetragen haben. Diese Parameter werden dann so angepasst, dass der Fehler kleiner wird.
Der Vorgang ist aufwendig und mathematisch anspruchsvoll:
- Gradienten Abstieg: Ein Optimierungsalgorithmus, der bestimmt, in welche Richtung und wie stark die Parameter verändert werden müssen, um den Fehler zu minimieren.
- Kettenregel der Differenzialrechnung: Sie erlaubt es, die Fehlerweitergabe Schicht für Schicht effizient zu berechnen – auch in sehr tiefen Netzwerken.
Dieser Trainingsprozess wird viele Male wiederholt – sogenannte Epochen. Nach jeder Epoche wird das Modell ein bisschen besser. Und irgendwann ist es genau genug, um eingesetzt zu werden.
Ab dann beginnt die Phase der Inferenz – also das Nutzen des trainierten Modells.
Doch: Dieser Prozess ist langwierig, benötigt viel Rechenleistung und ist entsprechend teuer – vor allem bei großen Netzwerken.
Beim Training unterscheiden wir drei grundlegende Methoden#
- Supervised Learning: Beim überwachten Lernen zeigen wir dem Modell gelabelte Daten – also Daten, bei denen das gewünschte Ergebnis bereits bekannt ist. In unserem Beispiel wäre das ein Bild einer Ziffer, bei dem direkt dabeisteht, welche Ziffer es darstellt. Das Modell kann dann den Unterschied zwischen seiner Vorhersage und der realen Lösung erkennen – und daraus lernen.
- Unsupervised Learning: Hier präsentieren wir dem Modell ungelabelte, rohe Daten. Es bekommt keine Hinweise – und versucht selbst, Muster oder Strukturen in den Daten zu erkennen. Es gruppiert z. B. ähnliche Daten – man spricht von Clustering. Spannend dabei: LLMs wie ChatGPT wurden technisch gesehen mit unbeschrifteten Texten aus dem Internet trainiert – aber mithilfe sogenannter Self-Supervised Learning-Methoden. Sie erzeugen sich dabei intern „eigene Labels“ – mehr dazu später.
- Reinforcement Learning: Das Modell (bzw. der „Agent“) lernt durch Belohnung und Bestrafung, wie es sich beim nächsten Mal besser verhalten kann. Diese Methode wird z. B. eingesetzt, um Spiele zu meistern – oder bei ChatGPT für das sogenannte Reinforcement Learning from Human Feedback (RLHF), das oft nach dem eigentlichen Pretraining zum Feintuning verwendet wird.
Besteht das Modell den Test?#
Wie prüfen wir, ob ein trainiertes Modell wirklich etwas taugt?
Nachdem wir das Netzwerk mit vielen Beispielen trainiert haben und der Fehler (Loss) ausreichend klein ist, müssen wir sicherstellen, dass es die Daten nicht einfach nur auswendig gelernt hat.
Stattdessen soll es gelernte Muster auch auf neue, unbekannte Daten übertragen können – das nennt man Generalisierungsfähigkeit.
Dazu teilen wir den Datensatz, zum Beispiel mit 1.000 Bildern, in zwei Teile:
800 Bilder verwenden wir zum Trainieren, die restlichen 200 Bilder halten wir zurück und nutzen sie erst später zum Testen.
Erkennt das Modell auch diese neuen Bilder zuverlässig – also solche, die es im Training noch nie gesehen hat –, dann gilt es als generalisiert und brauchbar für den Praxiseinsatz.
Saubere Daten: Der Schlüssel zum Erfolg#
Der Spruch: “Du bist, was du isst” – gilt auf für neuronale Netzwerke.
Damit ein Modell zuverlässig Muster erkennen kann, müssen die Trainingsdaten akkurat, vollständig und von hoher Qualität sein. Wird ein Netzwerk beispielsweise mit verrauschten oder falsch belichteten Bildern von Hunden und Katzen trainiert, wird auch das Ergebnis – wenig überraschend – mäßig ausfallen.
Bias, Fehlinformation oder schlechte Qualität in den Trainingsdaten wirken sich direkt auf das Verhalten des Modells aus – mit potenziellen ethischen Folgen.
Ein leistungsfähiges Modell braucht daher:
- Gute Datenqualität: Fehlerfrei, genau und konsistent
- Datenvielfalt: Unterschiedliche Varianten, Blickwinkel und Kontexte
- Verifizierte Daten: Wahr, glaubwürdig und überprüft
- Bereinigte Daten: Fehler, Ausreißer und Duplikate entfernen
- Normalisierte Werte: Einheitliche Skalen, z. B. bei Helligkeit oder Pixelwerten
- Repräsentative Daten: Relevante Beispiele für alle Anwendungsszenarien
- Aktuelle Daten: Auf dem neuesten Stand und kontextuell passend
Erstes Fazit#
Neuronale Netze sind mächtige Werkzeuge, aber keine Magie. Sie lernen, erkennen Muster, ziehen Schlussfolgerungen – und können uns im Alltag enorm unterstützen. Aber: Damit das zuverlässig funktioniert, brauchen sie ein durchdachtes Design und vor allem saubere, vielfältige und aktuelle Daten. Fehlerhafte, einseitige oder veraltete Daten führen unweigerlich zu fehlerhaften Ergebnissen.
Was wir für unser LLM Verständnis mitnehmen können#
- Neuronale Netze werden nicht klassisch programmiert, sondern lernen selbstständig, Muster in Daten zu erkennen.
- Datenqualität ist entscheidend: Schlechte, fehlerhafte oder inkonsistente Daten führen zu schlechten Ergebnissen – Garbage in, garbage out.
- Das Training ist rechenintensiv und zeitaufwendig. Erst nach Abschluss des Trainings wird aus dem Netz ein fertiges Modell, das im Einsatz verwendet wird (→ Inferenz).
- Nach dem Training sind die Modellparameter fixiert – das heißt: Das neuronale Netz lernt im Einsatz nichts mehr dazu, es ist statisch.
- Gelernt wird durch Anpassung von Gewichten und Bias-Werten – diese nennt man Parameter.
- Die Aktivierungsfunktion bestimmt, wie Signale weitergeleitet werden – z. B. für Merkmalsextraktion (ReLU) oder Klassifizierung (Softmax).
- Neuronale Netze liefern immer eine Antwort – selbst wenn keine passende dabei ist. Dann wird die wahrscheinlichste, aber womöglich falsche Lösung präsentiert.
- Tiefe neuronale Netze (Deep Neural Networks) haben viele versteckte Schichten (Hidden Layers) – ab etwa 3 spricht man meist von „deep“.
- Die Entscheidungen solcher Netze sind schwer nachvollziehbar – weil sie auf der Aktivität tausender oder sogar Millionen Neuronen basieren. Die Erklärbarkeit bleibt eine offene Herausforderung.
© 2025 Oskar Kohler. Alle Rechte vorbehalten.Hinweis: Der Text wurde manuell vom Autor verfasst. Stilistische Optimierungen, Übersetzungen sowie einzelne Tabellen, Diagramme und Abbildungen wurden mit Unterstützung von KI-Tools vorgenommen.