
Wie kann ich Dokumente intelligent nutzen?#
Dieses Problem existiert bereits seit vielen Jahren:
Unternehmen sitzen auf einem riesigen Berg wertvoller interner Dokumente in unterschiedlichsten Formaten. Wissen, Regeln, Anweisungen, Tipps und Erfahrungen wurden über Jahre hinweg dokumentiert, gesammelt und an den verschiedensten Orten abgelegt.
Es ist ein enormer Schatz an Wissen – doch sobald man darauf zugreifen möchte, scheint er unauffindbar zu sein. Man weiß, dass die Information irgendwo existiert, doch niemand weiß mehr genau, wo sie abgelegt wurde.
Viele Unternehmen kennen dieses Problem nur zu gut. Immer wieder wird versucht, Ordnung in dieses Dokumentenchaos zu bringen und eine sinnvolle Struktur zu etablieren. Doch das ist in der Praxis oft schwieriger als gedacht. Selbst wenn man sich auf eine einheitliche Struktur geeinigt hat, bleiben Herausforderungen bestehen: Inhalte sind doppelt vorhanden, wurden mehrfach aktualisiert oder widersprechen sich an einzelnen Stellen.
Häufig versucht man, dem Ganzen mit strikten Ordnerhierarchien, Namenskonventionen und Volltextsuche Herr zu werden. Trotzdem kostet die Suche nach den passenden Dokumenten viel Zeit – ganz abgesehen davon, dass die gefundenen Dateien erst mühsam gesichtet werden müssen, um die tatsächlich relevante Information zu finden.
Wie praktisch wäre es, stattdessen einfach Fragen stellen zu können – und ein hilfreicher Assistent beantwortet sie direkt auf Basis der unternehmenseigenen Dokumente?
Welche Richtlinie gilt in diesem Fall?
Was muss ich hier beachten?
Große Sprachmodelle als Game Changer#
Bis vor Kurzem war dies leider noch Wunschdenken. Doch dank aktueller Fortschritte in der KI – insbesondere durch große Sprachmodelle wie ChatGPT, Gemini oder Mistral – ist genau das inzwischen realistisch umsetzbar.
Diese Sprachmodelle sind in der Lage, Texte semantisch zu verarbeiten und Fragen auf Basis vorgegebener Texte zu beantworten. Dabei geht es nicht um reines Stichwortsuchen, sondern um das Verstehen von Zusammenhängen und Bedeutungen im Text.
Trainiert werden diese Modelle auf Textvervollständigung: Sie lernen, auf Basis des bisherigen Kontexts das wahrscheinlich nächste Token vorherzusagen und einen Text dadurch schrittweise sinnvoll zu vervollständigen.
Wir nutzen LLMs wie ChatGPT und ähnliche Modelle heute praktisch täglich, und viele können sich ein Leben ohne sie kaum noch vorstellen. Die Handhabung ist dabei erstaunlich einfach:
Wir geben dem LLM etwas Kontext in Form eines Prompts, und das Modell vervollständigt diesen.
Stellen wir eine Frage, erhalten wir – im Idealfall – eine passende Antwort. Dieses Wissen bezieht das LLM aus seinem Weltwissen, also aus den Daten, mit denen es trainiert wurde.
Fortschrittliche Modelle nutzen darüber hinaus Function Calling oder ähnliche Mechanismen, um sich zusätzliche Informationen aus externen Quellen, etwa aus dem Internet, zu beschaffen.
Wie bringen wir nun unsere eigenen Dokumente ins Spiel?#
Für allgemeines Wissen funktioniert das bereits sehr gut. Doch wie stellen wir Fragen zu eigenen Dokumenten – etwa zu einer PDF-Datei?
Im Prinzip scheint auch das ganz einfach zu sein:
Wir extrahieren den Text (und gegebenenfalls auch Bilder und Tabellen) aus dem Dokument, kopieren ihn in das Chatfenster und stellen anschließend unsere Frage. Als Antwort erhalten wir – idealerweise – Informationen, die direkt aus dem Dokument stammen.
flowchart TD
subgraph A[📄 PDF-Verarbeitung]
A0[📄 PDF] --> A1[🧰 Text extrahieren]
end
subgraph B[❓ Anfrage]
B0[💬 Nutzerfrage] --> B1[🧾 Prompt]
A1 --> B1
end
subgraph C[✨ Generierung]
B1 --> C0[🤖 LLM]
C0 --> C1[📝 Antwort]
end
So unkompliziert das zunächst klingt, verbergen sich dahinter jedoch einige grundlegende Probleme:
- Das Herauskopieren relevanter Informationen aus Dokumenten kann bereits beim Copy-and-Paste mühsam und fehleranfällig sein.
- Wir müssen dem Modell sehr genau vorgeben, wie es sich verhalten soll, damit es kein eigenes Weltwissen beimischt oder halluziniert.
- Bei großen Dokumenten stoßen wir schnell an die Grenzen des Kontextfensters – also an die maximale Textmenge, die ein LLM gleichzeitig verarbeiten kann.
- Der Kontext bleibt nur erhalten, weil das Dokument Teil des Chatverlaufs ist. Wird es nicht erneut mitgeschickt oder fällt aus dem Kontextfenster, ist es für das LLM nicht mehr verfügbar.
- Durch die hohe Anzahl an Tokens kann dieser Ansatz sehr schnell teuer werden.
- Zudem können wir auf diese Weise immer nur einzelne Dokumente mitgeben – in der Praxis ist relevantes Wissen jedoch häufig auf Hunderte oder Tausende von Dokumenten verteilt.
Retrieval-Augmented Generation (RAG)#
Die grundlegende Idee ist einfach:
Zu einer Frage werden relevante Abschnitte aus den vorhandenen Dokumenten herausgesucht und dem Prompt als zusätzlicher Kontext mitgegeben. Das LLM verfügt dadurch über genau die Informationen, die es benötigt, um die Frage dokumentengetreu zu beantworten.
flowchart TD
subgraph D[📚 Dokumente vorbereiten]
D0[📄 Dokumente] --> D1[🧰 Inhalte extrahieren]
end
D1 --> K[📚 Wissensbasis]
Q[💬 Nutzerfrage] --> R[🔎 Relevante Inhalte finden]
K --> R
R --> P[🧾 Prompt mit Kontext]
P --> L[🤖 LLM]
L --> A[📝 Antwort]
Wichtig ist dabei: Die Dokumente werden nicht vollständig, sondern nur selektiv eingebunden – also genau die Textstellen, die für die jeweilige Frage relevant sind.
Auf diese Weise lassen sich mehrere der zuvor beschriebenen Kernprobleme direkt lösen:
Durch die gezielte Auswahl relevanter Ausschnitte können Inhalte aus vielen Dokumenten gleichzeitig berücksichtigt werden, ohne das Kontextfenster zu sprengen oder die Tokenkosten explodieren zu lassen.
Gute Vorbereitung ist alles#
Damit das LLM schnell und gezielt auf relevante Inhalte zugreifen kann, müssen die Dokumente vorab aufbereitet werden.
Zunächst gilt es, die Dokumente in eine für Maschinen lesbare Form zu überführen. Anschließend werden die Inhalte in kleinere Einheiten aufgeteilt und indexiert, sodass ein schneller Zugriff möglich ist – vergleichbar mit einer Datenbank.
Dokumente in eine lesbare Form bringen#
Dieser erste Schritt ist deutlich anspruchsvoller, als es auf den ersten Blick scheint. Dokumente liegen in der Praxis in den unterschiedlichsten Formaten vor: einfache Textdateien, Word-Dokumente, E-Mails, PDFs, Webseiten und vieles mehr.
Bei einfachen Texten, Word-Dateien oder E-Mails ist die Extraktion meist unproblematisch. Anders sieht es bei PDFs oder Webseiten aus. Diese enthalten oft komplexe Formatierungen, Tabellen, Bilder, Layouts oder sogar interaktive Elemente.
Im Idealfall werden alle relevanten Inhalte vollständig extrahiert, die inhaltliche Hierarchie beibehalten und Bilder sowie Tabellen dem jeweils passenden Text zugeordnet. Gerade bei Webseiten, E-Mails oder PDFs stellt das jedoch häufig eine große Herausforderung dar.
Für diese Konvertierung kommen unterschiedliche Ansätze zum Einsatz: von selbstgebauten Extraktionspipelines über Dokumentenkonvertierungslösungen bis hin zu spezialisierten Parsern wie Docling. Je nach Aufbau und Qualität der Quelldokumente kann dieser Schritt relativ einfach – oder nahezu ein unlösbares Problem sein.
Das Ziel ist im optimalen Fall eine strukturierte, hierarchische Repräsentation der Inhalte, die als Grundlage für alle weiteren Verarbeitungsschritte dient.
Dokumente in kleinere Happen aufteilen#
Nachdem wir die Daten in eine einheitliche, lesbare Form gebracht haben, werden die Dokumente in kleinere Einheiten zerlegt – sogenannte Chunks.
Diese Aufgabe übernimmt ein Splitter.
Je nach Art und Struktur des Dokuments kommen dabei unterschiedliche Strategien zum Einsatz:
vom einfachen Längenschnitt, über rekursive Splitter, bis hin zu Verfahren, die Inhalte hierarchisch entlang von Überschriften, Absätzen oder Abschnitten aufteilen.
Damit die einzelnen Chunks ihren inhaltlichen Zusammenhang nicht verlieren, wird in der Praxis meist ein Overlap verwendet. Dabei wird ein Teil des vorherigen und nachfolgenden Inhalts in jeden Chunk übernommen, um Kontext zu erhalten.
Dieser Schritt ist ein essenzieller Bestandteil der RAG-Pipeline, denn die Chunk-Größe hat einen maßgeblichen Einfluss auf die Qualität der Ergebnisse:
- Zu kleine Chunks trennen Informationen, die eigentlich zusammengehören.
- Zu große Chunks packen zu viel auf einmal hinein, sodass das Wichtige untergeht.
Auch der Overlap spielt dabei eine entscheidende Rolle. Häufig werden Faustregeln wie 200–800 Tokens Chunk-Größe bei etwa 10–20 % Overlap genannt. Diese Werte sind jedoch keine festen Vorgaben, sondern hängen stark vom Dokumenttyp und dem konkreten Anwendungsfall ab.
Bewährt haben sich Stichproben, um zu prüfen, ob einzelne Chunks für sich verständlich und sinnvoll in den Gesamtkontext einzuordnen sind. Diese Prüfung kann manuell erfolgen, lässt sich in vielen Fällen aber auch automatisiert unterstützen.
Bedeutung statt Wörter speichern#
Nun haben wir unsere lesbaren Häppchen – diese möchten wir so abspeichern, dass wir sie später schnell und gezielt wiederfinden können.
Das Ziel ist, zu einem großen Dokumentenpool Fragen zu stellen und dabei genau die relevanten Chunks zu erhalten.
Früher hätte man diese Chunks einfach in einer klassischen Datenbank gespeichert und über eine Volltextsuche abgefragt – mit, wie wir wissen, oft mäßigen Ergebnissen. Die Suche bleibt dabei stark wortbasiert und berücksichtigt dabei kaum Bedeutung oder inhaltliche Nähe.
Embedding - die Bedeutung eines Worts#
Dank moderner Transformer-Modelle können wir heute einen deutlich effektiveren Ansatz verfolgen:
Statt nur den Text zu speichern, speichern wir dessen Bedeutung. Dieser Vorgang wird als Embedding bezeichnet.
LLMs werden auf Textvervollständigung (Next-Token-Prediction) trainiert.
Embedding-Modelle hingegen werden darauf optimiert, semantische Ähnlichkeit abzubilden.
Typischerweise geschieht dies mithilfe von Textpaaren (z. B. Frage/Antwort oder thematisch verwandte Texte). Das Ziel ist, inhaltlich ähnliche Texte im Embedding-Space nahe beieinander zu platzieren.
In den Grundlagen auf dieser Webseite beschreibe ich die Technologie hinter Embeddings ausführlicher. An dieser Stelle fasse ich das Prinzip bewusst vereinfacht noch einmal zusammen.
Wem das Thema Embeddings geläufig ist, kann diesen Absatz überspringen.
Einzelne Wörter – genauer gesagt Tokens – werden anhand einer Vielzahl von Merkmalen (man könnte auch von Eigenschaften sprechen) beschrieben und als Punkte in einem mehrdimensionalen Raum abgelegt.
Nehmen wir als vereinfachtes Beispiel eine Katze. Mit drei Eigenschaften – etwa flauschige Ohren, Fellnase und große Augen – ließe sich eine Katze in einem dreidimensionalen Raum darstellen: eine Dimension pro Eigenschaft.
Erhöhen wir die Anzahl der Dimensionen, können entsprechend mehr Eigenschaften gleichzeitig berücksichtigt werden. Mit acht Dimensionen wären es acht Eigenschaften, mit sechzehn entsprechend sechzehn. Moderne Embedding-Modelle arbeiten jedoch mit sehr viel höheren Dimensionalitäten, zum Beispiel 1.536 Dimensionen, und können damit eine entsprechend feingranulare Beschreibung der Bedeutung eines Tokens abbilden.
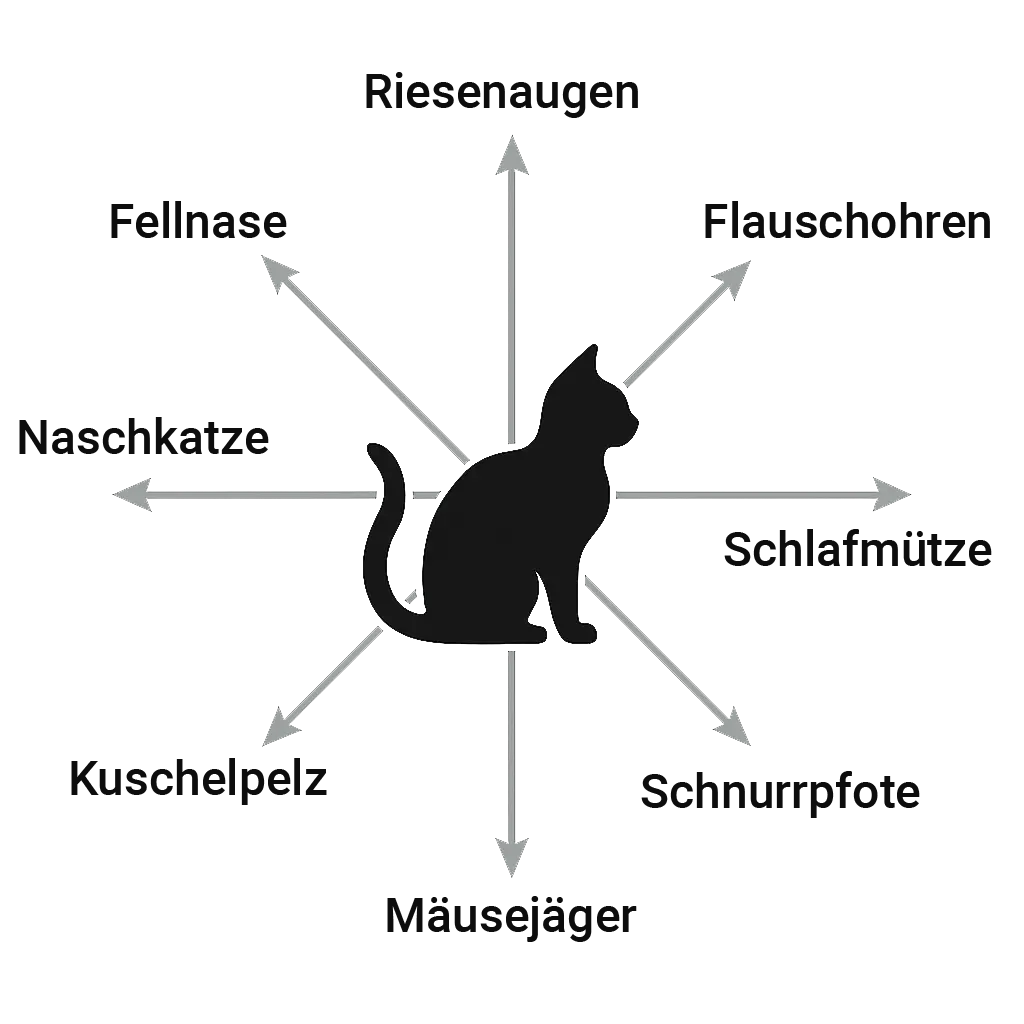
Dies ist nicht nur eine Metapher zur besseren visuellen Vorstellung – der Merkmalsraum wird mathematisch tatsächlich als geometrischer Raum modelliert, in dem Abstände und Richtungen berechnet werden können.
Wichtig dabei: Die Eigenschaften einzelner Wörter oder Begriffe werden nicht manuell festgelegt oder beschriftet. Stattdessen lernt das Modell diese Merkmale automatisch während des Trainings auf großen Textmengen. Man spricht hierbei von latenten Merkmalen, da sie zwar wirksam sind, für uns Menschen jedoch nicht direkt interpretierbar.
Das Ziel ist es, Begriffe mit ähnlicher Bedeutung im Raum nahe beieinander abzubilden.
Der Abstand zwischen ihnen drückt dabei die semantische Nähe aus.
Worte mit ähnlichen Merkmalen – etwa Katze, Hund oder Haustier – gruppieren sich in einer Region des Merkmalsraums, während Begriffe wie Auto, Fahrrad oder Lkw sich in einer anderen Region konzentrieren.
Alle Wörter (Tokens) eines Chunks werden nun embedded – das heißt, sie werden in eine Position in einem mehrdimensionalen Vektorraum überführt.
Das Ergebnis ist ein numerischer Vektor, zum Beispiel (0.1, 0.23, …), mit einem Zahlenwert pro Dimension.
Verschiedene Anbieter stellen heute unterschiedliche Embedding-Modelle zur Verfügung, darunter zum Beispiel E5, OpenAI oder Cohere.
Betrachten wir einen Chunk mit beispielsweise 500 Tokens. Würde man jedes Token einzeln als Vektor mit 1.536 Dimensionen darstellen, ergäbe das pro Chunk 768.000 Zahlenwerte. Das ist unhandlich und lässt sich später nur schwer effizient vergleichen.
Deshalb verfolgen wir einen anderen Ansatz:
Jeder Chunk wird als Ganzes durch einen einzigen Vektor beschrieben. Dieser Vektor dient als eine Art kompakter Fingerabdruck für den gesamten Inhalt des Chunks.
Pooling#
Das Verfahren, aus vielen Token-Vektoren einen einzigen Fingerabdruck für den gesamten Chunk zu berechnen, nennt man Pooling.
Dabei gibt es verschiedene Pooling-Strategien, zum Beispiel Mean Pooling, Max Pooling, CLS-Token oder Weighted Pooling.
Für RAG-Anwendungen wird in der Praxis häufig Mean Pooling eingesetzt. Dabei wird für jede Dimension der arithmetische Mittelwert über alle Token-Vektoren eines Chunks berechnet. Konkret bedeutet das:
Jede einzelne Dimension aller Token wird aufsummiert und anschließend durch die Anzahl der Tokens geteilt – eine klassische Mittelwertberechnung.
Durch dieses Verfahren werden die semantischen Merkmale aller Tokens eines Chunks zusammengeführt.
Erstaunlicherweise liefert diese einfache Methode in vielen Anwendungsfällen stabile und gut vergleichbare Ergebnisse.
Je nach Embedding-Modell ist dieser Pooling-Schritt intern umgesetzt oder explizit auswählbar.
Speichern in der Datenbank#
Nun können wir den Chunk-Vektor gemeinsam mit dem zugehörigen Text in einer Vektordatenbank speichern.
Dadurch lassen sich die Inhalte später schnell, zuverlässig und semantisch wiederfinden.
Zur Auswahl stehen verschiedene Vektordatenbanken, die jeweils ihre eigenen Vor- und Nachteile haben. Dazu zählen zum Beispiel Pinecone, Weaviate, Qdrant, Milvus oder ChromaDB.
Für Tests und Prototypen (MVPs) eignet sich ChromaDB besonders gut, da es leichtgewichtig, einfach aufzusetzen und lokal nutzbar ist.
Für den produktiven Einsatz greifen Unternehmen hingegen häufiger zu Pinecone, Weaviate oder Qdrant, da diese Lösungen besser auf Skalierbarkeit, Stabilität und Betrieb in Produktionsumgebungen ausgelegt sind.
Frage deine KI#
RAG-Systeme sind in Unternehmen oft der erste Berührungspunkt mit KI. Sie lassen sich vergleichsweise einfach implementieren und liefern schnell einen konkreten, messbaren Mehrwert.
Für Mitarbeitende ist das besonders praktisch, um Fragen zu internen Richtlinien, Prozessen oder dem unternehmensweiten Wissenspool zu stellen. Gleichzeitig profitieren auch Kundinnen und Kunden, etwa bei Fragen zu Öffnungszeiten, Produkten oder Services.
In der Praxis erfolgt die Interaktion häufig über eine Chatoberfläche, die an bekannte KI-Systeme erinnert. Alternativ wird das System direkt in eine bestehende Infrastruktur integriert, zum Beispiel in Microsoft Teams oder ähnliche Kollaborationstools.
Dabei gilt: Je unauffälliger und natürlicher die Integration, desto besser wird KI von den Menschen angenommen.
Wie findet RAG die relevanten Chunks?#
In der Praxis stellt ein Nutzer eine Frage, zum Beispiel: „Wie sind die Öffnungszeiten?“
Nun ist es Aufgabe des RAG-Systems, auf Basis dieser Anfrage die relevanten Chunks zu finden und daraus eine möglichst passende Antwort zu generieren.
Der Ablauf ist dabei sehr ähnlich zu dem Prozess, den wir bereits beim Embedding der Dokumente kennengelernt haben:
- Die Frage des Nutzers wird zunächst in Tokens zerlegt.
- Anschließend wird die gesamte Frage embedded und – je nach Modell – gepoolt. Dadurch erhält sie eine Position im Embedding Space, also im mehrdimensionalen latenten Vektorraum.
- Die Chunks, die im Vektorraum am nächsten zu dieser Frage liegen, sind diejenigen, die uns interessieren.
Ganz wichtig dabei ist, dass für das Embedding der Chunks und für das Embedding der Nutzerfrage dasselbe Embedding-Modell und dieselben Parameter verwendet werden.
Andernfalls liegen Frage und Dokumente in unterschiedlichen Vektorräumen – sie „sprechen“ dann nicht dieselbe Sprache und lassen sich nicht sinnvoll miteinander vergleichen.
Wie finden wir heraus, welche Chunks am nächsten zu unserer Frage sind?#
Dazu messen wir die räumliche Distanz zwischen dem Vektor der Nutzerfrage und den Vektoren der gespeicherten Chunks.
Chunks mit dem geringsten Abstand gelten als semantisch am ähnlichsten und werden für die Beantwortung der Frage herangezogen.
Wie man den geometrischen Abstand zwischen Vektoren misst, habe ich in den Grundlagen auf dieser Webseite bereits ausführlich erklärt.
Ich greife den Punkt hier noch einmal kurz auf, um den Zusammenhang klarzumachen.
Geometrische Nähe im Embedding-Raum#
Grundlegend gibt es drei Möglichkeiten, die räumliche Nähe zu messen:
- Euklidische Distanz
Dabei wird der geometrische Abstand zwischen zwei Vektoren über alle Dimensionen berechnet.
Anschaulich entspricht das der „geraden Linie“ zwischen zwei Punkten im Vektorraum.
Für alle, die es mathematisch mögen:
Die euklidische Distanz ist einfach die Länge der Geraden zwischen zwei Punkten, berechnet nach dem Satz des Pythagoras.
Als Beispiel gilt für 3 Dimensionen: $$ d(\mathbf{x}, \mathbf{y}) = \sqrt{(x_1 - y_1)^2 + (x_2 - y_2)^2 + (x_3 - y_3)^2} $$
In der allgemeinen Form für (n) Dimensionen schreibt man kompakter:
$$ d(\mathbf{x}, \mathbf{y}) = \sqrt{\sum_{i=1}^{n} (x_i - y_i)^2} $$
- Skalares Produkt (Dot-Produkt)
Die Ähnlichkeit von Wörtern lässt sich auch über den Winkel und die Länge der Vektoren ihrer Embeddings verstehen.
Man kann sich das so vorstellen: Je kleiner der Winkel zwischen den Vektoren zweier Wörter ist, desto ähnlicher sind ihre Bedeutungen.
Für alle, die es wieder mathematisch mögen:
Man multipliziert die einzelnen Komponenten (Hadamard-Produkt) und summiert anschließend die Ergebnisse.
So entsteht ein einzelner Wert, der die semantische Ähnlichkeit ausdrückt.
- nahe 0 → kaum Ähnlichkeit
- positiv → semantisch ähnlich
- negativ → eher gegensätzlich
$$ \mathbf{x} \cdot \mathbf{y} = \sum_{i=1}^{n} x_i , y_i $$
- Kosinus-Ähnlichkeit
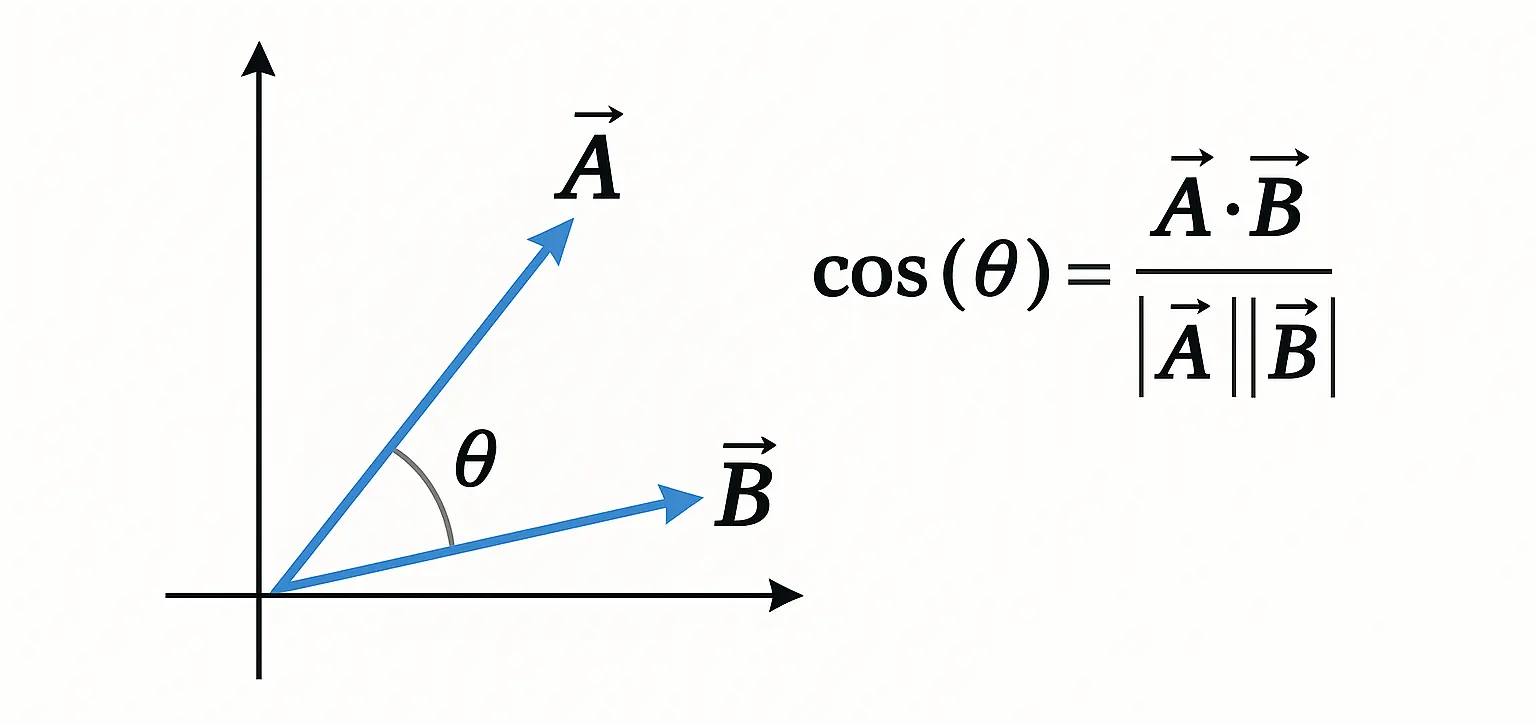
Die Kosinus-Ähnlichkeit geht noch einen Schritt weiter und ist ein normalisiertes Skalarprodukt.
Das bedeutet: Es wird nur der Winkel zwischen den Vektoren betrachtet, unabhängig von ihrer Länge.
Das Ergebnis liegt immer zwischen –1 und 1.
Wie auch bei den anderen Verfahren fließen alle Dimensionen der Embeddings in die Berechnung ein.
Für alle Matheliebhaber:
$$ \cos(\theta) = \frac{ \vec{A} \cdot \vec{B} }{ | \vec{A} | \cdot | \vec{B} | } $$
Die Formel misst, wie ähnlich zwei Wort-Embeddings im semantischen Raum ausgerichtet sind.
- Im Zähler steht ihr Skalarprodukt – also wie stark sie in die gleiche Richtung zeigen.
- Im Nenner das Produkt ihrer Längen – wodurch die Werte normiert werden.
Das Ergebnis liegt zwischen –1 und 1:
Je näher an 1, desto ähnlicher sind die Bedeutungen der Wörter.
| Verfahren | Idee | Wertebereich | Typischer Einsatz |
|---|---|---|---|
| Euklidische Distanz | Geometrischer Abstand im Raum | 0 → ∞ | Clustering, Abstandsmaße |
| Skalares Produkt | Berücksichtigt Winkel und Vektorlängen | –∞ → +∞ | Attention, Ranking, Scores |
| Kosinus-Ähnlichkeit | Winkel zwischen Vektoren (normiert) | –1 → +1 | Semantische Suche, Retrieval |
In vielen RAG-Systemen lässt sich eines dieser Distanz- bzw. Ähnlichkeitsverfahren konfigurieren.
In der Praxis werden Embedding-Vektoren oft normalisiert, sodass ihre Länge keine Rolle mehr spielt und beim Vergleich nur noch die inhaltliche Richtung zählt.
Nur die besten kommen in die Auswahl#
In der Praxis übergeben wir der Vektordatenbank die Nutzerfrage (als Embedding) sowie die gewünschte Anzahl an Treffern (k).
Die Vektordatenbank berechnet daraufhin, welche Chunks der Anfrage semantisch am nächsten liegen, sortiert sie nach Ähnlichkeit und liefert die Top-k relevantesten Chunks zurück.
Anfrage an das LLM#
Die Anfrage an das LLM erfolgt in Form eines Prompts. Dabei werden die System-Anweisung, die relevanten Chunks sowie die Nutzeranfrage zu einem gemeinsamen Kontext zusammengeführt und in einer Anfrage an das LLM gesendet.
In der Praxis wird die System-Anweisung häufig auf Englisch formuliert – selbst dann, wenn der eigentliche Kontext und die Nutzerfrage deutsch sind. Der Grund dafür ist, dass die Stabilität und Zuverlässigkeit von Instruktionen bei den meisten LLMs in englischer Sprache höher ist.
{
"messages": [
{
"role": "system",
"content": "You are a helpful assistant. Answer only based on the provided context. If the answer is not contained in the context, say that you do not know."
},
{
"role": "user",
"content": "Context:\n---\n[Chunk 1]\n[Chunk 2]\n[Chunk N]\n---\n\nQuestion:\nWie sind die Öffnungszeiten?"
}
]
}Mit dieser Anweisung vervollständigt das LLM die Nutzeranfrage gemeinsam mit dem bereitgestellten Kontext zu einer sinnvollen, zusammenhängenden Antwort.
{
"role": "assistant",
"content": "Unsere Öffnungszeiten sind Montag bis Freitag von 08:00 bis 17:00 Uhr."
}In vielen Systemen werden zusätzlich die verwendeten Textstellen referenziert oder mitgeliefert, um Antworten nachvollziehbar zu machen.
Am Ende dieses Prozesses steht ein funktionsfähiges RAG-System, das Antworten auf Grundlage der hochgeladenen Dokumente generiert.
Die RAG-Pipeline im Überblick#
flowchart TD
%% INDEXING
subgraph A[📚 Indexing]
A0[📄 Dokumente] --> A1[✂️ Chunking]
A1 --> A2[🔤 Tokenisierung]
A2 --> A3[🧠 Transformer Encoder]
A3 --> A4[🧩 Token Vektoren]
A4 --> A5[📊 Pooling z.B.: Mean]
A5 --> A6[📐 Chunk Vektor]
A6 --> A7[(🗄️ VectorDB)]
end
%% QUERY
subgraph B[❓ Query]
B0[💬 User Query] --> B1[🔤 Tokenisierung]
B1 --> B2[🧠 Transformer Encoder]
B2 --> B3[🧩 Token Vektoren]
B3 --> B4[📊 Pooling z.B.: Mean]
B4 --> B5[📐 Query Vektor]
end
%% RETRIEVAL
subgraph C[🔍 Retrieval]
B5 --> C1[🔎 Similarity Search]
A7 --> C1
C1 --> C2[📌 Top-k Chunks]
end
%% GENERATION
subgraph D[✨ Generation]
D0[🧾 Prompt + Kontext + Frage] --> D1[🤖 LLM]
D1 --> D2[📝 Antwort]
end
C2 --> D0
Unsere RAG-Pipeline ist bereits voll funktionsfähig – dennoch lässt sie sich weiter verbessern.
Die Antworten basieren primär auf semantischer Ähnlichkeit. Das ist der große Fortschritt – und in den meisten Fällen genau richtig. Manchmal möchte man jedoch ganz gezielt exakte Details finden, zum Beispiel Nummern, IDs oder konkrete Fehlermeldungen. In solchen Fällen ist ein rein semantischer Ansatz nicht immer die beste Wahl.
Gespür für Details - BM25#
Hier kann ein klassisches Retrieval-Verfahren helfen: BM25 (Best Matching 25).
BM25 basiert auf Wortstatistiken und kommt ohne KI aus. Die Grundidee ist einfach: Seltene Wörter sind oft besonders aussagekräftig – vor allem dann, wenn sie in wenigen, aber relevanten Textstellen auftauchen (z. B. eine eindeutige Fehlermeldung oder ein spezieller Fachbegriff).
BM25 nutzt dabei unter anderem folgende Größen:
- Term Frequency (TF): Wie oft kommt ein Wort in einem Chunk vor?
- Document Frequency (DF): In wie vielen Chunks kommt dieses Wort insgesamt vor?
- Dokumentlänge: Wie lang ist der Chunk im Vergleich zu anderen?
In Kombination mit Embeddings entsteht so ein robustes Hybrid-Retrieval:
Embeddings liefern Textverständnis und finden auch ähnliche Formulierungen, während BM25 besonders gut bei exakten Begriffen, Fehlercodes und Fachtermini ist.
Beim Chunking der Dokumente werden die Chunks sowohl in einen BM25-Textindex aufgenommen als auch parallel als Embeddings in der Vektordatenbank gespeichert.
Hybrid RAG#
Beim hybriden RAG werden für eine Nutzeranfrage zwei Suchen parallel ausgeführt: eine semantische Vektorsuche auf Basis von Embeddings und eine statistische, wortbasierte Suche mit BM25.
Beide Verfahren liefern jeweils ihre Top-k Chunks, die anschließend zusammengeführt und weiterverarbeitet werden.
flowchart TD
%% INDEXING
subgraph A[📚 Indexing]
A0[📄 Dokumente] --> A1[✂️ Chunking]
A1 --> A2[🧠 Embedding Model]
A2 --> A3[📐 Chunk Embeddings]
A3 --> A4[(🗄️ Vector Database)]
A1 --> A5[🔤 Tokenization]
A5 --> A6[(🗂️ BM25 Text Index)]
end
%% QUERY
subgraph B[❓ Query]
B0[💬 User Query] --> B1[🧠 Embedding Model]
B1 --> B2[📐 Query Embedding]
B0 --> B3[🔤 Tokenization]
end
%% RETRIEVAL
subgraph C[🔍 Retrieval]
B2 --> C1[🔎 Vector Search]
A4 --> C1
C1 --> C2[📌 Top-k Vector]
B3 --> C3[🔎 BM25 Retrieval]
A6 --> C3
C3 --> C4[📌 Top-k BM25]
C2 --> C5[🔀 Merge / Re-ranking]
C4 --> C5
C5 --> C6[📌 Final Top-k Chunks]
end
%% GENERATION
subgraph D[✨ Generation]
C6 --> D0[🧾 Prompt: Context + Question]
D0 --> D1[🤖 LLM]
D1 --> D2[📝 Answer]
end
Hier kommt im Retriever eine zusätzliche Komponente ins Spiel: Merge / Re-Ranking.
Denn wir erhalten zwei getrennte Ergebnislisten – einmal aus der Vektorsuche und einmal aus BM25. Diese Kandidaten müssen wir zusammenführen, nach Relevanz sortieren und anschließend auf ein finales Top-k begrenzen.
Dafür gibt es unterschiedliche Strategien, zum Beispiel:
- score-basiert (Scores werden normalisiert und kombiniert)
- ranking-basiert (Ränge werden zusammengeführt, z. B. über Rank-Fusion)
Besonders gute Ergebnisse liefern Transformer-Modelle als Re-Ranker. In der Praxis sind zwei Ansätze verbreitet:
Cross-Encoder Re-Ranker
Ein Modell, das Query und Chunk gemeinsam bewertet und daraus einen Relevanzscore ableitet. Solche Modelle sind typischerweise für Relevanzbewertung (Ranking) optimiert.LLM Re-Ranking (z. B. per GPT)
Ein klassisches LLM, das per Prompt dazu angeleitet wird, die Kandidaten-Chunks nach Passgenauigkeit zur Frage zu sortieren oder die besten k auszuwählen.
Anschließend gehen die Nutzeranfrage und die passendsten Chunks in die Generation-Pipeline, wo das LLM daraus eine möglichst passende und informative Antwort auf die Frage des Nutzers erzeugt.
Millionen von Vektoren? – Hierarchical Navigable Small World (HNSW)#
Spätestens bei großen RAG-Systemen stellt sich die Frage, wie sich Millionen multidimensionaler Vektoren in akzeptabler Zeit durchsuchen lassen. Ein exakter Vergleich aller Vektoren wäre hier zu langsam.
In der Praxis kommen daher approximative Ähnlichkeitssuchen zum Einsatz – Verfahren, die sich schrittweise an die relevantesten Vektoren annähern.
Ein häufig verwendeter Ansatz ist HNSW (Hierarchical Navigable Small World), der von vielen Vektordatenbanken eingesetzt wird.
Das Prinzip lässt sich gut mit einem Straßennetz vergleichen:
Vektoren werden in mehreren Hierarchieebenen organisiert. Die obersten Ebenen sind sehr dünn besetzt und entsprechen gewissermaßen Autobahnen, über die man schnell große Distanzen zurücklegt. Die darunterliegenden Ebenen werden zunehmend dichter und bilden feinere lokale Verbindungen ab – vergleichbar mit Landstraßen und Nebenstraßen.
Die Suche beginnt immer in der obersten Ebene. Dort wird der Vektor gesucht, der der Anfrage am ähnlichsten erscheint. Von diesem Punkt aus wechselt der Algorithmus in die nächsttiefere, dichter vernetzte Ebene und setzt die Suche fort. Dieser Vorgang wiederholt sich Ebene für Ebene, bis die unterste und detaillierteste Ebene erreicht ist.
Auf diese Weise nähert sich die Suche gezielt dem Zielvektor, ohne alle Vektoren vergleichen zu müssen.
Das ermöglicht eine sehr schnelle Ähnlichkeitssuche, insbesondere bei großen Vektormengen, bei gleichzeitig hoher Trefferqualität.
Grenzen von RAG#
Moderne LLMs machen es erstmals möglich, intelligente Frage-Antwort-Systeme auf Basis bestehender Dokumente zu realisieren. Dennoch sollten bei RAG-Systemen einige grundlegende Einschränkungen berücksichtigt werden.
Datenqualität ist entscheidend
RAG kann nur mit den Informationen arbeiten, die tatsächlich extrahiert wurden. Gerade bei komplexen Formaten wie PDFs, Webseiten oder E-Mails ist die zuverlässige Extraktion von Text, Struktur und Kontext häufig eine große Herausforderung.Verlust von Kontext durch Chunking
Durch die Aufteilung von Dokumenten in einzelne Chunks können Zusammenhänge verloren gehen. Aufgaben, die ein globales Verständnis erfordern – etwa vollständige Zusammenfassungen oder Querverweise über mehrere Abschnitte hinweg – sind dadurch nur eingeschränkt möglich.Halluzinationen sind nicht vollständig ausgeschlossen
RAG reduziert Halluzinationen deutlich, verhindert sie jedoch nicht vollständig. Findet das System keine passenden Inhalte zur Anfrage oder sind die bereitgestellten Chunks unklar, kann das LLM weiterhin plausibel klingende, aber falsche Antworten erzeugen.Begrenzte Nachvollziehbarkeit
Ohne zusätzliche Maßnahmen ist oft nicht transparent, auf welchen Textstellen eine Antwort basiert. In der Praxis ist es daher sinnvoll, Quellen, Textausschnitte oder Positionsangaben mitzuliefern, um Ergebnisse überprüfbar zu machen.
© 2025 Oskar Kohler. Alle Rechte vorbehalten.Hinweis: Der Text wurde manuell vom Autor verfasst. Stilistische Optimierungen, Übersetzungen sowie einzelne Tabellen, Diagramme und Abbildungen wurden mit Unterstützung von KI-Tools vorgenommen.